안녕하세요, 소프트웨어 개발자 김종하 입니다.
왜 이 글을 썼는가
지금 연재하는 글은 "부트캠퍼를 위한 컴퓨터 과학" 입니다. 최근 소프트웨어 개발자 수요가 늘어나서 이를 공급하기 위한 코딩 부트캠프가 많이 생겼습니다. 지금 저와 함께 일하는 동료의 대부분도 부트캠프 출신입니다.
인도 카스트 제도처럼 출신에 따른 차별은 아니지만 4년이라는 긴 세월동안 교수님의 잔소리와 막중한 과제, 엄청난 삽질을 견뎌내며 컴퓨터 공학을 배운 학부생과 몇 달 동안 빠르게 코딩 스킬만 익힌 일반인과는 분명 차이가 존재합니다. 이는 부정할 수 없는 사실입니다. 부트캠퍼 주니어 개발자 중에 localhost:80와 localhost:8080의 차이가 뭔지도 모르는 사람도 봤습니다. 물론 웹에 관심없는 컴공 학부생도 모를 수 있겠지만, 80포트와 8080포트라는 사실은 알겁니다. 이런 기본적인 지식은 차치하더라도 전공자와 부트캠퍼와 가장 큰 차이는 배우는 속도와 피벗(Pivot)을 했을 경우 적응 시간입니다. 기본이 탄탄하면 피벗(Pivot)이 쉽습니다. 하지만 부트캠퍼 프론트엔드 개발자가 Node.js 말고 Rust 같은 언어를, 웹 말고 다른 분야를 도전할때 기초가 없으면 빠르게 적응하지 못합니다. 이론적 바탕이 없는 스킬은 그저 기예에 가깝습니다.
부트캠퍼 개발자들은 10명 중 6~7명은 웹 개발일겁니다. API를 개발하는 백엔드 개발자들은 물론이거니와 프론트엔드 개발도 단순히 리액트, CSS만 할 줄 알면 되는게 아니라 컴퓨터 과학 지식이 기반에 깔려야 좀 더 좋은 개발자들이 되리라 확신합니다. 따라서 저는 이 글을 저희 회사 내 부트캠프 출신 주니어 개발자를 독자로 상정하고 썼습니다.
어떻게 썼는가
이 글은 컴퓨터 공학 전문적인 영역을 깊게 파고드는게 아니라 컴퓨터 교양 수업에 가깝게 쓰도록 노력했습니다. 사실 학부 출신인 제가 깊게 써봤자 얼마나 깊게 쓰겠습니까. 다만 컴퓨터 공학 전공자분들은 하찮은 내용이라고 무시하지 마시고 사실이 아닌 부분에 대해서 많이 의견 주시면 감사하겠습니다. 특히 1학년때 배운 디지털 회로같은 과목은 들은지 10년이 훨씬 넘었으니까 틀렸을 수도 있습니다.
또한 이 글은 퇴고와 내용 변경이 수시로 일어나니 이 점 참고하시기 바랍니다.
전공자와 비전공자
회사 생활 연차가 두 자리를 넘어가는 동안 수 백명의 개발자를 만나봤습니다. 고등학교 갓 졸업한 사람, 부트캠퍼, 국비학원, 컴퓨터 공학사, 컴퓨터 공학 석사/박사, 문과 전공 개발자 등등. 그 결과 컴퓨터 공학 지식이 좋은 개발자가 되기 위해서 반드시 필요한 조건은 아니라는 사실을 깨달았습니다. 물론 알면 좋습니다. 하지만 일반적인 개발 업무를 처리하는데에는 컴퓨터 공학 지식이 차지하는 영역은 크지 않습니다. 그것보다 커뮤니케이션, 문서화, 도메인 지식, 견고한 코드 짜기 등등 평소 업무에 사용하는 스킬은 극단적으로 말하면 컴퓨터 공학 지식이 없어도 할 수 있습니다.
그러니 비전공자 여러분, 너무 자격지심 가지실 필요 없습니다.
전공자의 길
컴퓨터 공학 전공자는 그럼 무엇을 무기로 비전공자들과 싸워야 하느냐라고 반문할 수도 있습니다. 하지만 부트캠퍼가 응용 계층에 주력한다면 공학 전공자는 좀 더 전문적인 부분에서 두각을 나타낼 수 있습니다. 운영 체계, 정적 코드 분석(Static Code Analysis), 컴파일러, 코덱 등 기초 분야가 좋은 예입니다. 저도 몇 년 동안 정적 코드 분석 분야에서 일했습니다. 이 분야는 컴파일러나 프로그래밍 언어론 지식이 필요하며, 특히 OS, 컴파일러는 대학교 4년 동안 배운 지식을 총 동원해도 겨우 할까 말까할 부분입니다. 이런 분야는 부트캠퍼 개발자가 일하기 매우 매우 힘들며 사실 학사 출신도 쉽지 않습니다.
그 외에도 일반적인 서비스 기업에서도 트래픽이건 데이터건 인프라건 규모가 커지면 공학의 중요성이 커집니다. 데이터가 커지면 알고리즘 복잡도가 n에서 log(n)으로만 가도 엄청난 성능 향상을 기대할 수 있으며 수 많은 트래픽을 받아내기 위해서 스케일 업 작업이라던가 네트워크의 깊숙한 부분까지 만져야 할 수도 있으며 파서(Parser)를 설계할 일이 생길 수도 있습니다.
이럴때 배워뒀던 컴퓨터 공학이 빛을 발할 수 있습니다.
저자
김종하
- 현) 셀러노트 CTO
- email: kim.jongha 지메일
주의점
- 순서나 글의 내용은 예정 없이 변경될 수 있습니다.
- 글에 대해 문의점, 오타, 잘못된 내용이 있을 경우 여기에 이슈 제기를 해주시거나 Pull Request를 날려주십시오.
저작권
- 이 글의 저작권은 저에게 있습니다.
- 글의 내용을 복제하여 위키, 나무위키, 블로그, 웹사이트 등에 게시할 수 없습니다.
- 링크 및 SNS 공유는 허용합니다.
- 글의 내용을 재가공할 수 없습니다.
- 글의 내용을 상업적으로 사용할 수 없습니다.
- 글의 내용을 어떠한 형태로든 재배포할 수 없습니다.
- 웹 배포는 저자 외에는 할 수 없습니다
Release Note
여기 계신 분들은 버전명이 0. 으로 시작된다는 의미를 아시리라 생각됩니다.
- 0.3 3장 네트워크/인터넷 1차 완성
- 0.2 2장 컴퓨터 구조와 기초 완성
- 0.1 init. 1장 들어가기에 앞서, 2장 컴퓨터 구조와 기초 일부
Release Candidate
- 0.3.1 DNS 추가(1월 중)
- 0.3.2 라우팅, 클라우드 컴퓨팅 추가(1 ~ 2월 중)
컴퓨터의 등장
제가 컴퓨터공학과에 입학했을때 1학년 과목이 디지털 회로 설계, 컴퓨터 구조, 이산수학과 C 컴퓨터 프로그래밍이었습니다. 특히 디지털 회로 설계 숙제로 빵판에다가 게이트를 연결하면서 '컴퓨터공학과인데 왜 디지털 회로 설계를 배우지?'라는 의문이 있었지만 어느 누구 하나도 속 시원히 답변해주지는 못했습니다. 나중에 혼자서 공부해보니 컴퓨터공학과는 "컴퓨터란 무엇인가?"라는 의문으로 시작해서 자료구조, 알고리즘, OS, 프로그래밍 언어를 배움으로서 각종 컴퓨터 분야에서 일할 수 있는 "범용" 인재를 키워내는데 그 목적이 있었습니다.
결국 튜링머신을 알아야하며 기초적인 디지털 회로 설계를 알아야 "컴퓨터는 무엇인가"라는 질문에 대한 답변을 할 수 있습니다. 이 사실을 알았다면 즐겁게 디지털회로설계를 했을텐데요. 이 챕터에서는 튜링머신과 부울 논리 등의 컴퓨터의 기본 원리와 역사에 대해서 설명합니다.
튜링머신의 등장
매년 노벨상 시상식 즈음되면 온 세계가 시끌벅적하다. 많은 분들이 이미 언론을 통해서 알고 있겠지만 노벨상은 여러 학문 분야마다 시상한다. 노벨상 시상 분야에는 평화, 문학, 화학, 물리, 생리/의학, 경제학은 있지만 컴퓨터 분야는 없다. 노벨이 살아있을 당시 컴퓨터라는 물건은 존재하지 않았으니까. (참조: 뒤끝) 대신 컴퓨터 과학계에서는 노벨상에 비견되는 튜링상(Turing Award)이라는 상이 있다. 이 상의 이름은 컴퓨터의 탄생에 지대한 업적을 남긴 20세기 영국의 수학자 앨런 튜링(Alan Turing)에서 따왔다. 어느 정도 지대한가 물으면 앨런 튜링은 "컴퓨터의 과학의 아버지의 아버지"라고 불릴 정도이며 현대 컴퓨터의 구조는 모두 그가 설계한 튜링머신을 기반으로 하고 있다는 말로 대신하겠다. 따라서 컴퓨터 과학계 최고 권위를 나타내는 상의 이름은 당연히 '튜링상'이다.
20세기 수학자들의 꿈과 희망
컴퓨터는 튜링이 "내가 이런 멋진 기계를 만들어보겠다!"라고 작정을 하고 만든 물건이 아니었다. 재미있게도 20세기 수학자들의 꿈과 희망을 짓밟는 과정에서 나온 부산물에 불과했다.
20세기 초 독일의 다비트 힐베르트(David Hilbert)라는 위대한 수학자가 있었다. 흔히 "힐베르트 문제"라는 이름으로 불린 수학계에서 20세기에 풀어야할 가장 중요한 문제 23개 문제를 제시한 천재 수학자였다. 힐베르트는 꿈이 하나 있었다. 지금까지 수학자들이 어떠한 문제를 증명하기 위해 해왔던 과정을 자신이 살펴보니 몇 개의 추론 규칙을 반복해서 적용하는게 전부였다. 이런 규칙들을 찾아서 이를 기계적인 방식, 즉 자동으로 추론해주는 기계를 만들면 수학자들이 더 이상 고생하지 않으리라는 꿈이었다.
당시 수학계의 거장이었던 힐베르트의 이 제안은 유럽 수학계를 꿈과 희망에 부풀게 하기 충분했다. 그러나 이 꿈과 희망은 고작 3년 밖에 가질 못했다. 당시 25세에 불과한 신참내기 수학자 쿠르트 괴델(Kurt Gödel)이 자신의 논문 "《수학 원리》 및 관련 체계에서 형식적으로 결정될 수 없는 명제에 관하여1"을 통해서 힐베르트의 주장은 절대 이루어질 수 없다고 수학적으로 증명해버린 것이었다.

쿠르트 괴델의 사진. 출처: 위키피디아
{kind=link}
어떤 가설을 반박하기 위한 가장 쉬운 방법 중 하나는 그 가설의 반례를 들면 된다. "불완전성 정리"라고 불리는 이 증명은 기계적인 방법만으로는 참인지 거짓인지 판단할 수 없는 명제가 항상 존재하기 때문에 힐베르트가 고안한 기계는 불가능하다는 사실을 수학적으로 증명했다. 이 정리는 복잡하기 때문에 여기서 설명할 내용은 아니니까 관심있는 사람은 위키를 참조하기 바란다. 아무튼 괴델의 이 증명은 꿈과 희망에 부풀어있는 수학계를 발칵 뒤집어놓기에 충분했다. 그리고 수학자들마다 괴델의 증명을 확인하는 과정에서 이 증명이 맞다는 사실을 알게 된다.
앨런 튜링
앨런 튜링이 괴델의 증명을 접한건 1935년, 튜링이 막 케임브리지 대학의 수학과를 졸업한 때였다. 맥스 뉴먼 수학과 교수가 개설한 괴델의 증명에 대한 강의를 들은 튜링은 자신만의 방법으로 다시 증명할 수 있겠다고 생각했다. 이내 튜링은 자신의 생각을 정리해서 <계산 가능한 수에 대해서, 수리명제 자동생성 문제에 응용하면서>라는 제목으로 약 1년 후에 런던 수리학회에 논문을 제출했다.
논문 제목만 보면 컴퓨터와 전혀 상관 없을 것 같지만 훗날 앨런 튜링의 컴퓨터 공학의 아버지의 아버지라고 불린 이유가 바로 이 논문에서 괴델의 증명을 다시 한 번 증명하는데 쓰인 상상 속의 기계가 훗날 현대 컴퓨터의 원형이 되는 물건이었기 때문이다. 튜링은 이 논문에서 모든 계산을 할 수 있는 보편적 만능기계(Universal Machine)을 제시했다. 즉 힐베르트가 꿈꾸던 기계를 먼저 설계하고, 이 기계로도 풀 수 없는 문제가 있다는 반례를 제시함으로서 힐베르트의 주장이 이루어질 수 없다는 사실을 다시 한 번 증명했다.
이 논문에서 튜링이 정의한 기계(이하 튜링 머신)는 고작 몇 개의 굉장히 단순한 부품으로 이루어져 있다.
- 테이프
일정한 크기의 셀(Cell)로 나뉘어 있는 종이 테이프. 각 셀에는 기호가 기록되어 있으며 길이는 무한히 늘어날 수 있다.
- 헤드
테이프의 특정 한 셀을 읽고 쓰거나 좌우로 이동할 수 있는 제어장치
- 행동표
영어로는 Action Table이지만 한국어로는 명령테이블, 규칙표 등 다양한 이름이 존재한다. 현재 상태와 기호에 따라 할 일(Action)을 지정한 표(Table)다. 행동표에 의해서 튜링머신은 헤더를 오른쪽이나 왼쪽으로 움직일 수 있으며 헤더에서 기호를 읽어들일 수 있고 헤더를 통해 테이프의 내용을 다시 쓸 수도 있다. 또한 행동표에 의거 현재 기계의 상태를 변경할 수 있다.
- 상태 기록기
기계의 상태를 기록한다.
단순한 부품으로 이루어진 기계답게 튜링머신이 하는 일은 단순하다. 테이프 칸의 기호를 읽고 쓰면서 테이프 왼쪽이나 오른쪽으로 움직이는 일 뿐이다. 이 와중에 기계의 상태가 매번 변경되거나 유지된다.
그밖에 기계장치는 아니지만 테이프에 쓸 수 있는 유한한 기호의 집합, 튜링 머신이 가질 수 있는 상태 집합이 있다. 그 중 상태에는 2가지 상태가 들어간다.
개시 상태(Start state): 상태 기록기가 초기화된 상태 종료 상태(Halt state): 수행이 종료된 상태
백문이 불여일예제다. 실제 예제를 들어서 설명해보겠다.
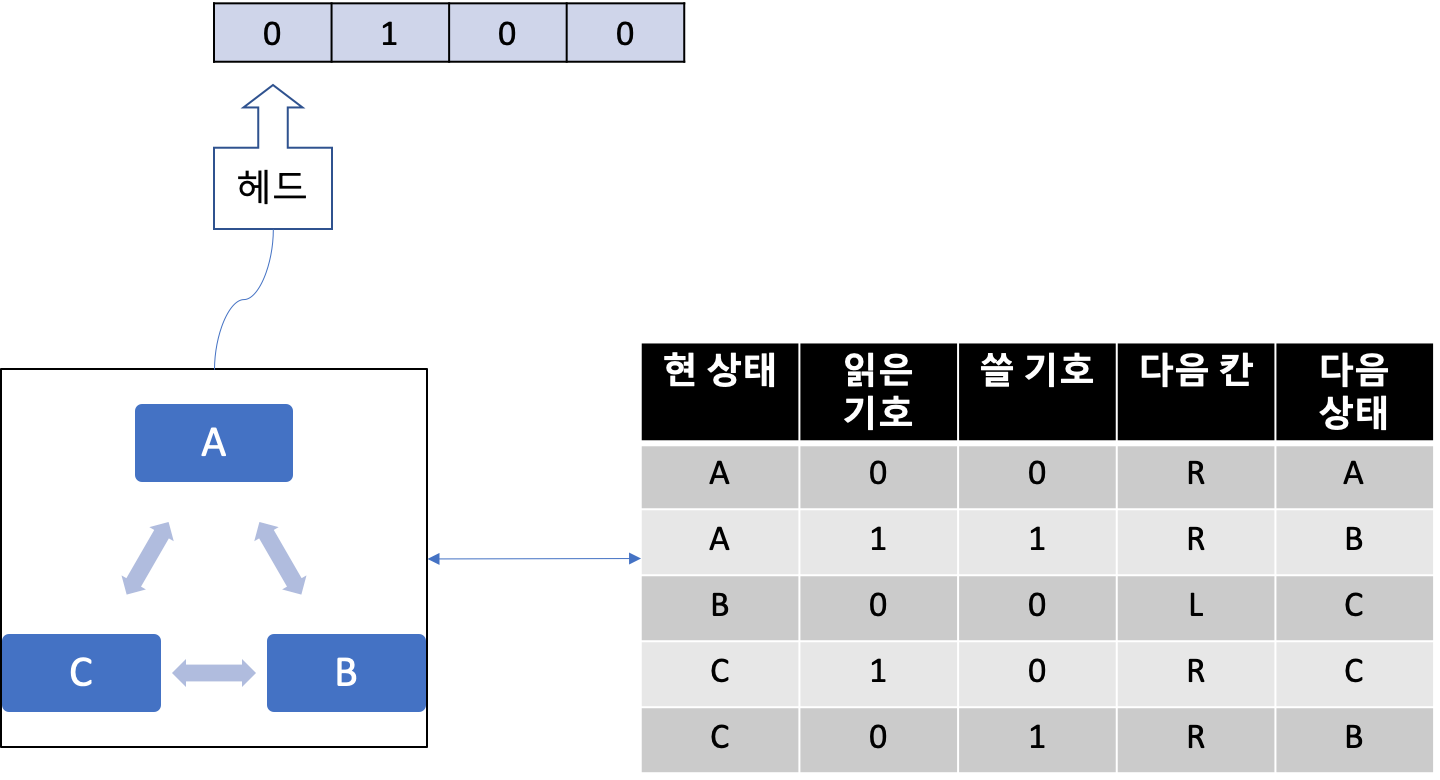
현재 기계의 상태가 A라고 가정한다. 그리고 테이프에서 첫 번째 칸을 읽는다. 예제에서는 0이다. 그렇다면 작동규칙표에서 현 상태 A와 읽은 기호가 0인 규칙을 찾는다. 첫 번째 줄이 해당 규칙이다. 이 규칙에 의거 읽은 곳에 0을 덮어 쓰고, 헤더를 오른쪽(R) 한 칸 이동하고 기계의 상태를 A로 바꾼다.
헤더는 다시 테이프를 읽는다. 방금 전 오른쪽으로 한 칸 이동했기 때문에 테이프의 2번째 칸 - 1이다. 현재 기계 상태가 A이고 읽은 기호는 1이기 때문에 작동규칙표의 두 번째 줄이다. 이 규칙에 의거 읽은 곳에 1을 쓰고 헤더를 오른쪽으로 한 칸 이동, 기계 상태를 B로 바꾼다.
헤더는 다시 테이프를 읽는다. 방금 전 오른쪽으로 한 칸 이동했기 때문에 테이프의 3번째 칸 - 1이다. 현재 기계 상태가 B이고 읽은 기호는 0이기 때문에 작동규칙표의 세 번째 줄이다. 이 규칙에 의거 읽은 곳에 0을 쓰고 헤더를 이번엔 왼쪽으로 한 칸 이동, 기계 상태를 C로 바꾼다.
헤더는 다시 테이프를 읽는다. 방금 전 왼쪽으로 한 칸 이동했기 때문에 테이프의 2번째 칸 - 1이다. 현재 기계 상태가 C이고 읽은 기호는 1이기 때문에, 작동규칙표의 네섯 번째 줄이다. 이 규칙에 의거 읽은 곳에 0을 쓰고 헤더를 오른쪽으로 한 칸 이동하고, 기계 상태를 C로 그대로 둔다.
헤더는 다시 테이프를 읽는다. 방금 전 오른쪽으로 한 칸 이동했기 때문에 테이프의 3번째 칸 - 1이다. 현재 기계 상태가 C이고 읽은 기호는 0이기 때문에, 작동 규칙표의 다섯 번째 줄이다. 이 규칙에 의거 읽은 곳에 1을 쓰고 헤더를 오른쪽으로 한 칸 이동, 기계 상태를 B로 바꾼다.
이 기계는 규칙표에 따라서 다양한 일을 할 수 있는데, 0만 쓰거나 1만 쓰거나 0과 1을 번갈라가면서 쓰는 일을 할 수 있고 사칙연산도 할 수 있다.
이쯤에서 우리 주변의 컴퓨터와 튜링머신을 비교해보면, 유사점을 많이 찾을 수 있다. 테이프는 메모리, 테이프에 읽고 쓰는 헤드는 메모리 입출력 장치, 작동규칙표는 CPU이며 테이프에 쓰인 기호의 집합은 현재의 소프트웨어라 볼 수 있다.
뒤끝
노벨 의학상은 의사가 받는게 아니라 보통 화학자가 받는 이유와 노벨 컴퓨터상이 없는 이유는 동일하다.
디지털의 등장
현대 컴퓨터의 원리는 튜링이 세웠다고 하지만 만약 상태 기록기가 기계식이었다면? 전자 회로를 별 이론적 체계가 없이 주먹구구식으로 만들었다면 개인용 컴퓨터가 집집마다 있고 모든 사람들 손에 스마트폰이 있는 세상은 오지 않았을 것이다. 대신 컴퓨터는 어마어마한 크기를 자랑하면서 대학교에나 가야 구경할 수 있는 진기명기가 되었을 것이다.
클로드 섀넌

클로드 섀넌. 출처: 위키피디아
{kind=link}
1936년 MIT를 졸업하고 전기공학으로 석사과정을 공부하던 클로드 섀넌(Claude Shannon)은 초기 아날로그 컴퓨터인 미분해석기를 연구하고 있었다. 섀넌은 특히 미분해석기의 전자 릴레이에 큰 흥미가 있었다. 전자 릴레이는 간단하게 말해서는 ON/OFF가 있는 일종의 스위치인데, 거실 불을 켜고 끌 수 있는 전등 스위치와는 다르게 이 릴레이는 자동으로 ON/OFF를 할 수 있게 해주는 전자부품이다. 내부에는 전자석이 있어서 전류가 걸리면 자성이 생겨서 스위치가 ON이 되며 전류가 없으면 자성이 없어져서 스위치가 OFF가 된다.
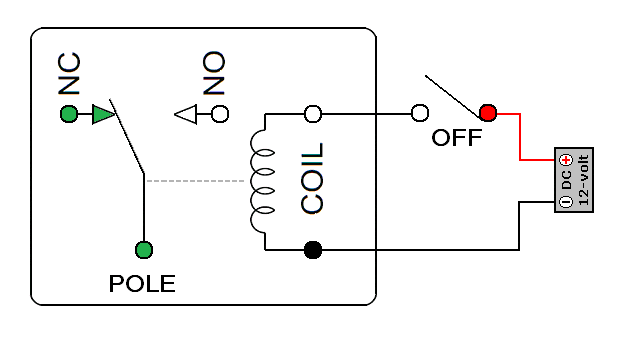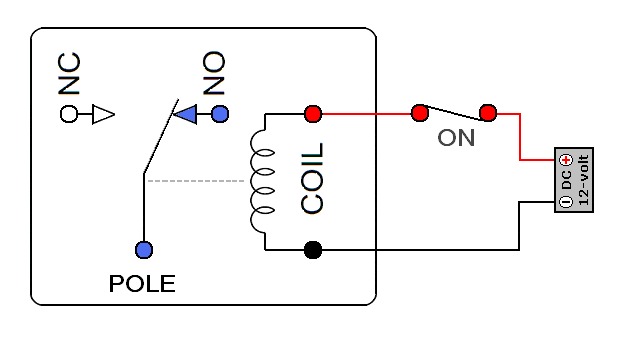
전자석의 동작 원리. 출처: 네이버 블로그
섀넌은 미분해석기의 논리 회로를 연구하면서, 부울(Bool) 논리식이 곧 스위치 회로가 같다는 사실을 깨달았다. 이 깨달음을 바탕으로 1937년 "계전기와 스위치로 이루어진 회로의 기호학적 분석"라는 기념비적인 "석사" 논문을 발표했다. 고작 25페이지에 불과한 이 탈석사급 레전드 논문은 이후 모든 디지털 컴퓨터의 설계에 영향을 미쳤다.
그렇다면 부울 논리식은 무엇이고 스위치는 어떻게 동작하는지 알아보자.
부울 논리식
1854년 영국 수학자 조지 부울(George Boole)은 "논리와 확률의 수학적 기초를 이루는 사고(思考)의 법칙 연구"이라는 책을 발표한다. 부울은 이 책에서 모든 명제(혹은 인간의 생각)은 AND, OR, NOT으로 결합하여 표현할 수 있다 보았고 이렇게 결합한 명제가 어떻게 참과 거짓으로 결정되는지 정리했다.
AND (그리고)
명제을 결합하는 방법 중 하나인 AND, 한국어로는 '그리고'는 두 명제를 결합했을 때 두 생각 모두가 참이면 그 결합한 결과 역시 참이다. (배우) "박서준은 남자다"라는 명제와 "박서준은 배우다"라는 명제를 합치면 "박서준은 남자다 그리고 배우다"라는 말이고 참이 된다. 허나 두 명제 중 하나라도 거짓이면 AND의 결과는 "박서준은 여자다 그리고 배우다" 처럼 거짓이 된다. 이렇게 AND의 경우 명제A와 명제B가 모두 참이여야 참이 된다. 참을 1, 거짓을 0으로 표현하면 아래와 같다,
| A | B | AB |
|---|---|---|
| 1 | 1 | 1 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 0 | 0 | 0 |
OR (또한)
명제를 결합하는 방법 중 또 다른 하나인 OR, 한국어로는 '또한'은 두 생각을 결합했을 때 두 명제 중 최소 하나가 참이면 그 결과 역시 참이다. '1 + 1 = 2이다.'와 '1 + 2 = 2이다.'라는 명제가 있다면 두 생각을 OR로 결합하면 '1 + 1 = 2이다 또는 1 + 2 = 2이다'이라서 참이 된다. 다만 '1 + 1 = 3이다 또는 1 + 2 = 2이다'은 두 명제 모두 거짓이기 때문에 이 결과도 거짓이다. 이를 표로 표현되면 아래와 같다.
| A | B | A+B |
|---|---|---|
| 1 | 1 | 1 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 0 | 0 | 0 |
NOT (아닌)
명제를 결합하는 마지막 방법인 NOT, 한국어로는 '아니다'는 참 거짓 여부가 반대로 된다. 예를 들어 "나는 살아있다"라는 명제가 있다. 물론 이 글을 읽고 있을테니까 참이겠다. 이를 NOT을 붙이면 "나는 살아있지 않다"가 되고 이는 당연히 거짓이 된다. 또한 "1+1은 3이다"는 거짓이다. 여기에 NOT을 붙이면 "1+1은 3이 아니다"가 된다. 이는 참이 된다. 이를 표로 표현되면 아래와 같다.
| A | -A |
|---|---|
| 1 | 0 |
| 0 | 1 |
결합
결합된 명제는 레고블럭처럼 다른 명제와 결합하는데 사용할 수 있다. 물론 결합은 AND, OR, NOT 이렇게 3가지 결합 방식을 사용해야 한다. 이렇게 명제를 계속해서 결합하면 더 큰 명제를 만드는데 쓰일 수 있다.
스위치
초등학교 과학 시간에 전구와 건전지, 전선을 가지고 전기에 대해서 배운 적이 있을 것이다. 이때 배우는 중요한 개념 중 하나가 직렬과 병렬이다.
예를 들어 건전지 2개를 직렬로 연결한 경우와 병렬로 연결한 경우를 살펴보자. 직렬 연결의 경우 이 건전지 2개 중 하나를 빼버리면 전구에 불이 안 들어온다.
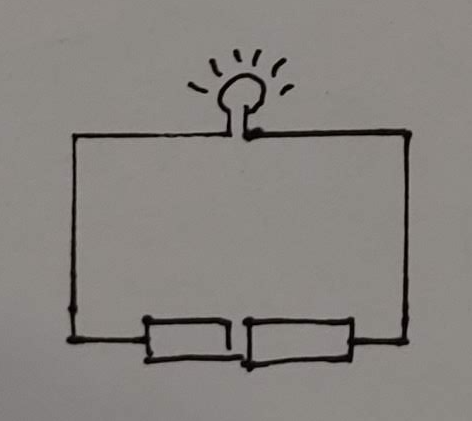
병렬 연결의 경우 이 건전지 2개 중 하나를 빼도 좀 어두워질지언정 불은 들어 온다. 병렬 연결의 경우 전구의 불을 끄려면 모든 전지를 빼내야 한다.
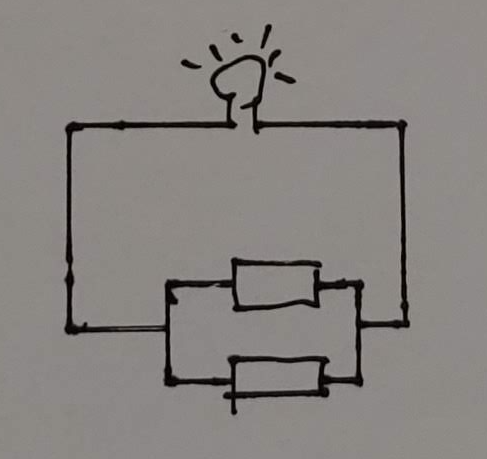
스위치의 배치도 마찬가지다. 전기가 왼쪽에서 오른쪽으로 흐른다고 가정한다면 직렬로 배치할 경우 두 스위치가 모두 ON이 되어야지 전기가 흐르며, 병렬로 배치할 경우 두 스위치 중 하나만 ON이 되어도 전기가 흐른다. 이쯤되면 눈치챈 사람도 있을텐데 직렬과 병렬은 각각 부울의 AND와 OR와 동일하다!
부울의 NOT에 해당하는 스위치도 동작 방식이 NOT과 똑같다. 결과가 무조건 반대인 NOT 스위치는 일종의 수문과 같다. 닫으면(ON) 단절되고 열면(OFF) 흐르는 스위치다.
그래서 뭐 어쩌라구?
셰넌이 공부하던 시절인 1930년대 전기 공학자들은 이 전자 릴레이를 이용하여 다양한 전자 회로를 만들고 있었다. 주로 이 전기 스위치를 '직렬' 혹은 '병렬' 혹은 '뒤집기'형태로 조합해서 원하는 작업을 할 수 있는 회로를 만들고 있엇는데, 공학은 공학이었지만 체계가 없었고 주먹구구식이었다. 이론과 체계가 없이 경험과 개개인의 스킬에 의존하면 더 크고 복잡한 제품을 만들지 못한다. 섀넌의 논문은 이 과정을 부울 논리로 깔끔하게 정리해주었다. 즉 스위치 회로 설계가 부울 대수 문제와 같다는 이야기로, 이는 곧 스위치 회로 설계의 이론적인 토대가 된다.
이후 이 전자회로 설계가 체계화되어 디지털 논리회로라는 이름으로 불리게된다.
참고: http://www.jobitoday.com/news/articleView.html?idxno=15853
디지털 논리 설계
디지털 논리 설계는 부울 대수에서 배웠던 AND, OR, NOT을 이용해서 유용한 디지털 회로를 체계적으로 설계하는 방법이다. 이를 위해선 몇 가지 순서가 있다.
- 입력 값과 출력 값을 정한다.
- 진리표를 만든다
- 진리표를 부울 대수로 간략하게 나타낸다.
- AND, OR, NOT 등의 스위치를 이용, 회로로 표현한다.
단계 1. 입력 값과 출력 값을 정한다
학습에 도움이 되기 위해, 문이 열리거나 사람의 움직임에 따라 자동으로 불이 켜지는 시스템을 설계해보자.
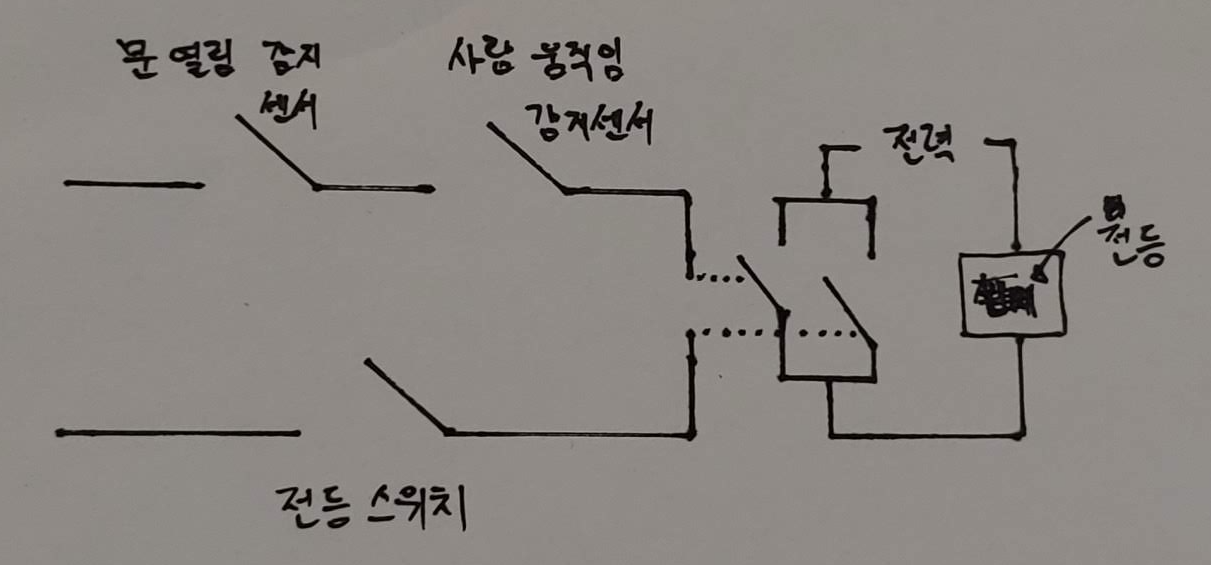
따라서 입력 값은 문의 열림을 탐지하는 센서가 주는 값, 사람의 움직임을 감지하는 센서가 주는 값, 전등 스위치 C의 ON/OFF 상태다.
출력은 단순하다. 전등이 켜지고 꺼짐이다.
단계 2. 진리표를 만든다
입력 값에 해당하는 센서와 스위치의 상태를 명제로 나타내면 아래와 같다.
x: 문이 열렸다.
y: 사람의 움직임이 탐지되었다.
z: 전등 스위치가 ON이다.
A: 전등이 켜진다.
각 센서와 스위치 상태에 따라 출력값을 진리표로 정리해보면 다음과 같다.
| x | y | z | A |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 |
| 0 | 1 | 0 | 0 |
| 1 | 1 | 0 | 0 |
| 0 | 0 | 1 | 0 |
| 0 | 1 | 1 | 1 |
| 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 |
단계 3. 진리표를 부울식으로 간략하게 나타낸다.
이 진리표를 표현하는 방법은 2가지가 있다. 하나는 부울식이며 하나는 기호로 표현할 수 있다. 부울식에서 AND, OR , NOT은 아래와 같이 표현한다.
- AND는 2개의 피연산자(A,B)가 있으며 이를 AB 혹은 A.B로 표현
- OR는 2개의 피연산자(A,B)가 있으며 이를 A+B로 표현한다.
- NOT은 1개의 피연산자가 있으며 이를 -A혹은 O로 표현한다.
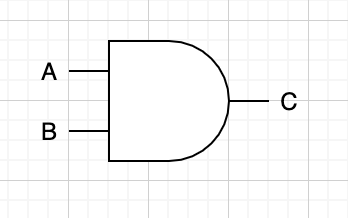
위의 진리표는 부울식으로 A = xy + z 와 같이 나타낼 수 있으며 이를 기호로 나타내면 아래와 같다. 아참, 그 전에 AND, OR, NOT을 기호로 표현하는 방식을 알아보자.
선 2개를 받아서 하나를 내놓는 반달 기호는 AND(그리고)를 표현한다. 기호 2개는 피연산자를 나타내고 1개는 결과값을 나타낸다.
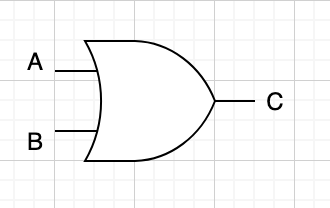
선 2개를 받아서 하나를 내놓는 초승달 기호는 OR(또는)를 표현한다. 입출력은 AND와 동일하다.
선 1개를 받는 삼각형과 작은 원이 조합된 기호는 NOT(아닌)을 표현한다. 피연산자는 1개 뿐이며 역시 1개의 결과값을 나타낸다.
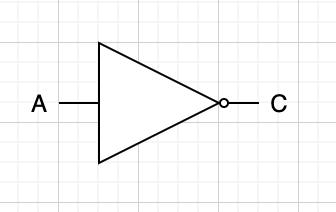
단계 4. AND, OR, NOT 스위치를 이용, 회로로 표현한다.
마땅한 예제가 떠오르지 않아서 퇴근길에 만난 자동 불켜짐 시스템을 가지고 예제를 꾸며봤는데 예제를 완성하고 보니 이 예제의 단점은 NOT 스위치는 쓰지 않는다... 나중에 더 좋은 예제가 나오면 예제를 바꿔보도록 하고 아무튼 이를 회로로 표현하면 다음과 같다.
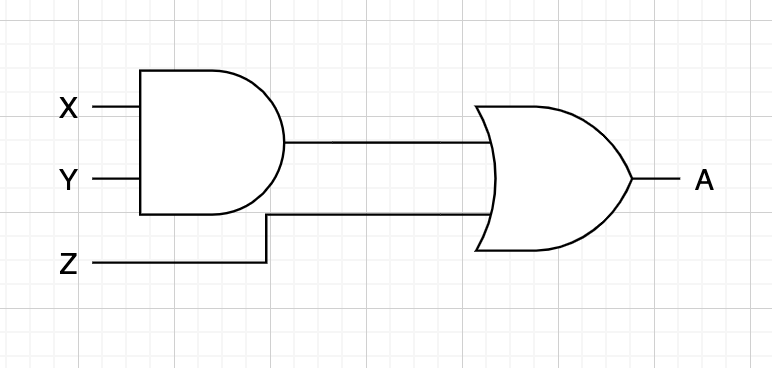
이 그림을 논리도(logic diagram) 혹은 회로도(circuit diagram)이라고 한다.
그런데 이거 어따 쓰나요? 음... 아래 그림같은 반도체 칩 본적이 있을지 모르겠다. 이건 IC7404칩의 사진이다.

7404칩은 NOT게이트 5개를 묶어서 사용하는 구조이다. 참고로 연산을 실제로 수행하는 하드웨어 소자를 게이트라고 한다.

14번과 7번은 전원을 제공하는 단자고 그 외 홀수 번은 입력, 짝수 번은 출력을 하는 단자이다. 위에서 예제로 든 자동 불켜짐 회로도 저렇게 하나의 칩으로 만들수 있다.
인텔이나 AMD가 만드는 CPU도 마찬가지다. 아래 회로도는 자일로그 Z80 CPU를 동작시키는 보드인데, 무슨 보드인지 이름을 모르겠지만, 여태까지 공부한 사람들은 대충 이게 뭔지는 보일 것이다.
CPU는 이런 스위치들이 굉장히 많이 모여 복잡한 일을 할 수 있는 장치라 보면 된다.
AND, OR, NOT 스위치로 기억회로 만들기
신기하게도 이 기본적인 스위치만으로 결과값을 기억할 수 있는 방법이 있다. 전혀 불가능한 일일것 같은데 아래의 회로를 살펴보자.
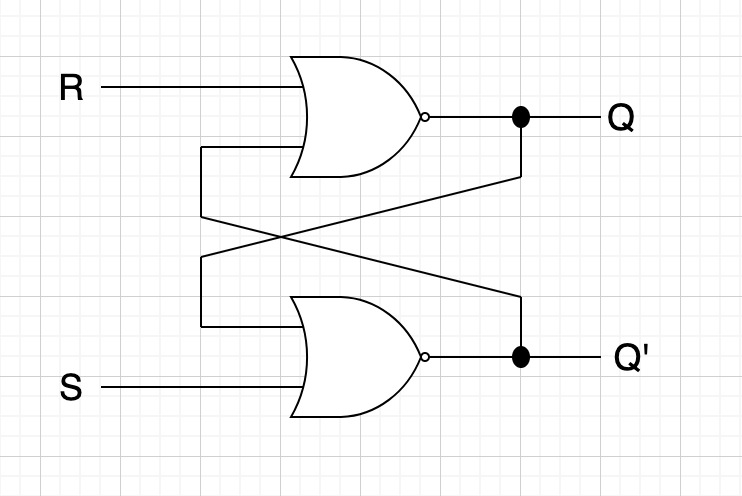
위 회로는 SR(set-reset) 래치라고 불리는 회로다. 여기서 S(set)는 출력 1을, R(reset)은 출력 0으로 되도록 한다는 의미이며, 저장된 현재 상태출력은 Q로 표시한다. 아 OR에 NOT을 의미하는 동그라미가 달린 게이트는 NOR게이트라고 불리며 진리표는 아래와 같다.
| A | B | A NOR B |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 0 | 0 |
| 0 | 0 | 0 |
| 0 | 0 | 0 |
보통 현업에서는 AND, OR 자체보다는 NAND, NOR, XOR, XAND 의 조합을 주로 많이 쓴다고 한다.
위의 상황을 수학식으로 표현해보자.
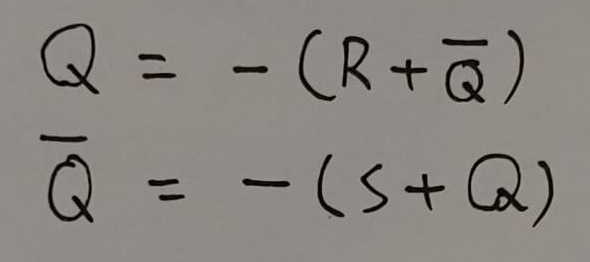
이 식에 따라 S와 R의 상태값 조합으로 메모리 Q에 0 혹은 1 값을 유지할 수 있다. S=1, R=0의 경우를 보자. 직관적으로는 그냥 1을 기억하라(Set)이라 할것 같은데 그게 맞다. S=1이기 때문에 Q'는 무조건 0이며 Q는 1이 된다. S와 R이 모두 0이면 Q는 1이다. S, R이 계속 0이면 Q는 계속 1값을 유지(저장)한다. 0을 쓰고 싶으면 왠지 리셋(Reset)하면 될 것 같은데 그게 맞다. S=0, R=1을 넣으면 Q는 0이 된다. 그 다음 S, R이 계속 0이 들어오면 Q의 값은 계속 0이 된다.
이 회로를 플립플롭(flip-flop) 혹은 래치라고 한다. 우리가 흔히 쓰는 메모리는 이 플립플롭이 모여서 구성된 장비이며 각 플립플롭마다 0 또는 1의 값을 저장하고 있다.
현대적 컴퓨터의 등장
컴퓨터는 모두 튜링머신을 기반으로 하지만 지금 사용하는 범용 컴퓨터 설계의 기반은 미국의 천재 수학자 존 폰 노이만의 설계를 기반으로 하고 있다. 폰 노이만은 1945년 EDVAC이라는 컴퓨터를 설계했다. 폰 노이만의 설계 문서에는 어디에서도 튜링의 논문에 대한 언급은 없지만 우연의 일치인지, 같은 천재끼리 통하는 무언가가 있는지 폰 노이만의 컴퓨터의 설계는 근본적으로 튜링 머신과 동일했다. 많은 이들이 폰 노이만이 튜링의 논문을 읽었다라고 추측은 하고 있지만 진실을 알 수는 없다. 이 컴퓨터가 할 수 있는 일이라면 어떠한 튜링 머신도 할 수 있는 일이다(참고로 이를 튜링 완전Turing Complete 하다고 한다)
폰 노이만 구조
폰 노이만 구조와 튜링 머신과의 가장 큰 차이는 '저장된 프로그램'(stored program)개념 유무다. 폰 노이만이 이 개념을 들고 나온데는 시조새급 컴퓨터 애니악(ENIAC, Electronic Numerical Integrator And Computer)의 프로그래밍 문제 때문이었다. 애니악에서 프로그래밍이라는건 바로 전 섹션에서 설명한 바와 같은 AND, OR, NOT 등의 스위치와 전선을 이어서 논리를 만들어야 하는지라 구현에 며칠씩 걸리곤 했다. 그리고 또 다른 프로그램을 애니악에 실행시키고 싶으면 하드웨어를 전면적으로 바꿔야 했다.
반면 폰 노이만 구조는 프로그램을 하드웨어가 아닌 "임의 접근이 가능한 메모리" 상에 올려서 이를 실행하는 방식이다. 따라서 컴퓨터에 다른 일을 시키고 싶다면 하드웨어 교체가 없이 프로그램만 변경하면 된다.
이 이론을 바탕으로 7년 후인 1952년, 케임브리지 대학교의 의뢰로 세계 최초의 프로그램 내장 방식 컴퓨터 EDSAC을 제작한다. 이후에 나온 컴퓨터는 모두 폰 노이만의 설계를 기본 구조로 설계되고 있다.
진공관과 트랜지스터
초창기의 논리 게이트는 진공관으로 만들어졌다. 진공관은 과거에는 전자회로에 굉장히 많이 사용되었지만 요즘에는 진공관 앰프같은 특수 분야에서만 사용되고 있기 때문에 실생활에서는 쉽게 찾아보기 힘들다. 아마 실물을 못본 사람들이 대다수일 것이다(사실 나도 실물은 본 적이 없다). 간단하게 말하자면 현대의 백열전구와 비슷하다고 보면된다. 아 요즘 LED전구만 봐서 백열전구가 뭐냐구요? 음....
진공관은 장점보다는 단점이 많다. 실제로 백열전구와 구조적으로도 비슷한 물건이기 때문에 비슷한 단점을 가지고 있는데, 전구니까 부피가 크고 유리로 되어 있어서 내구성이 약하다. 또한 전력을 많이 소모해서 열도 많이 났기 때문에 주변 환경에 취약하다. 애니악을 운영할 때도 수시로 터지는 진공관 때문에 운영에 꽤 애를 먹을 정도였으니까. 초기 컴퓨터 애니악은 18,000개의 진공관을 사용했기 때문에 무게만 30톤에 이르렀으며 200KW에 달하는 막대한 전력을 필요로 했다.
이후 진공관이 트랜지스터로 대체되었다. 트랜지스터는 진공관 대비 많은 장점이 있었다. 부피도 작고, 내구성도 강하고, 전력 효율적으로 동작했으며 싸고 대량 생산이 가능했다. 이후 집적회로가 발명되면서 손가락 한 마디만한 크기에 수 십 ~ 수 백 억개의 트랜지스터를 집적시킬 수 있었고, 그 결과 컴퓨터의 소형화가 가능하게 되었다. 요즘 인텔과 AMD의 CPU 경쟁에서 언급되는 몇 나노(nm)공정이 바로 일정 면적 안의 트랜지스터 집적 수준을 나타내는 지표인데, 2017년 10nm 공정을 적용한 스냅드래곤 835 프로세서에 집적된 트랜지스터 수는 약 30억개이며, 이듬해 화웨이가 7nm 공정의 기린 980 프로세서에 집적한 트랜지스터의 수는 약 69억 개 수준으로 2배 이상 증가한 수치를 보여준다. 참고로 1971년 초기 PC 한 대에 사용된 트랜지스터의 수는 약 2300개에 불과했다.
P.S 집적도의 향상이 곧 향상된 성능을 보장하는건 아니다.
컴퓨터 구조와 기초
챕터1에 배운건 컴퓨터 구조(Computer Architecture)의 입문에 가깝습니다. 사실 제가 입학 후 1달 정도 학교를 안나가느라 수업을 못들어서 튜링머신을 몰랐나봅니다. -_-. 원래 이번 챕터는 컴퓨터 구조를 다루려고 했으나 컴퓨터 구조만 다루기에는 양이 너무 적고 컴퓨터 구조의 극히 일부만 다루므로, 컴퓨터 구조와 컴파일러 소개, 운영체제(OS, Operating System) 소개까지 덧붙여 "컴퓨터 구조와 기초"라는 제목으로 아래 내용을 다룹니다.
- 메모리
- CPU란 무엇인가, CPU에 일 시키기
- 컴퓨터에서 수의 표현(a.k.a. 이진수)
- 컴파일러란?
- 운영체제란?
사실 이번 챕터에 다루려고 했던 컴퓨터 구조는 꽤 방대한 과목이고 컴퓨터 공학에서 꽤 중요한 과목입니다. 보통 컴퓨터 구조에서 다루는 내용은 다음과 같습니다.
- 컴퓨터 개론
- 디지털 논리 회로(조합논리 회로, 순서논리 회로)
- CPU(산술 논리 연산장치, 레지스터, 컴퓨터 명령어)
- 어셈블리어
- 제어장치(명령어 사이클, 파이프라이닝)
- 기억장치(캐시, 주/보조기억장치, 페이징)
- 보조기억장치
- 인터럽트
- 병렬 컴퓨팅
주니어 웹 개발자 아니 거의 다수의 웹 개발자들은 직접적으로 컴퓨터 하드웨어를 다루지 않기 때문에 이 모든 내용을 알 필요는 없습니다. 다만 시스템 프로그래밍, OS에 관심있으신 분은 한 번 읽어보셔도 좋습니다. 예전에 자신만의 OS를 만든다고 나댔을때 사실 가장 도움 많이되는것은 Intel x86 Architecture 책하고 이 컴퓨터 구조였습니다. 네, 사실 부트로더까지만 만들고 printk도 못 만들었죠.
메모리
흔히 우리가 RAM이라 불리는 장치가 메모리다. 튜링 머신의 테이프에 해당하는 장치이며 폰 노이만 구조의 '임의 접근이 가능한 메모리'에 해당한다. 컴퓨터가 수행해야할 명령어를 저장하거나 연산에 필요한 데이터를 저장하는 목적으로 사용된다.
메모리의 원리
메모리는 수 많은 플립플롭 회로로 구성되어 있다. 챕터 1의 디지털 논리설계의 마지막에서 언급한 0 혹은 1을 저장하는 회로가 바로 그것이다. 참고로 하나의 플립플롭이 저장하는 0 또는 1을 하나의 비트bit라고 하고 이 8비트를 1바이트byte라 부른다. 요즘 흔히 쓰는 16 기가바이트는 128,000,000,000개의 플립플롭 회로를 사용한다고 생각하면 된다. 그리고 메모리는 수 많은 셀로 나뉘어져 있는데, 이 셀마다 고유의 주소가 있어서 주소를 알면 바로 해당 주소에 해당하는 메모리의 값을 바로 읽을 수 있다.
메모리 동작 원리를 파악하기 위해 가장 간단한 4비트짜리 메모리를 예로 들겠다.
4비트 메모리는 주소가 총 4개가 있다. 각각 0, 1, 2, 3이라고 가정한다. 이를 이진수로는 00, 01, 10, 11이다. 그리고 이 주소 값을 넣어줄 전선 2개와 이 주소 값을 읽고 쓸 데이터를 위한 전선이 2개가 있다.
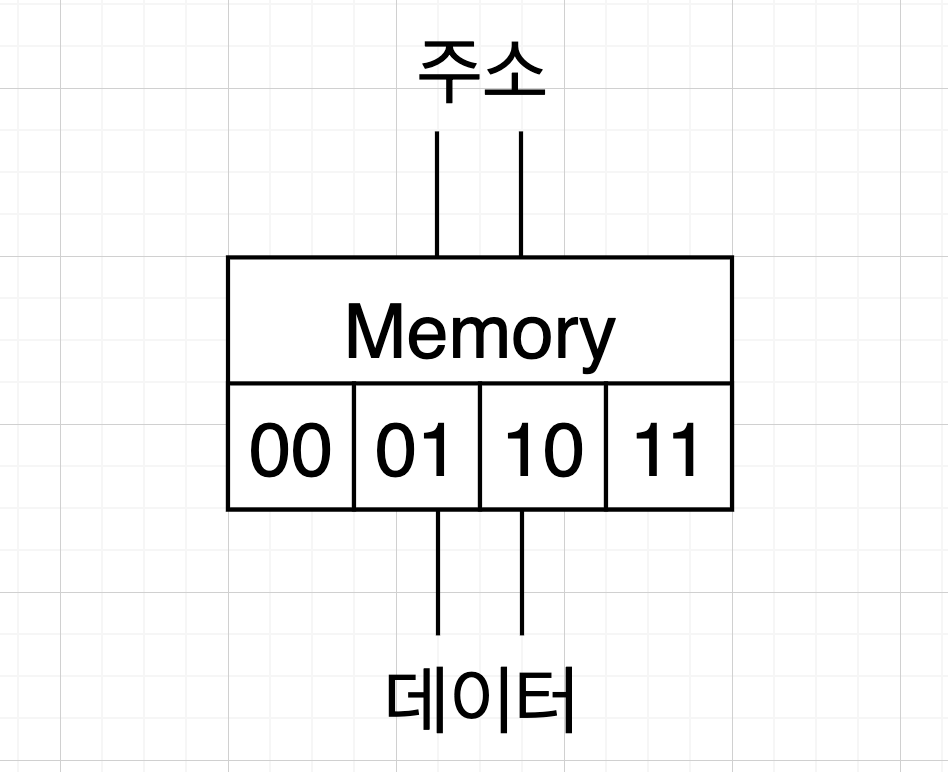
편의상 위의 전선 2가닥이 주소 전선, 아래 전선 2가닥이 데이터 전선이라고 칭한다.
만약 메모리에 저장되어 있는 2번 주소의 데이터를 읽고 싶다면 주소 전선을 통해 읽을 주소인 10을 넣어준다. 그러면 메모리는 해당 주소에 저장된 값을 데이터 전선으로 내보낸다. 참고로 읽을 주소를 넣어줄 전선은 괜히 2개를 그려놓은게 아니다. 4개의 주소를 표현하기 위해서는 두 자리의 이진수가 필요하기 때문이다. 참고로 8개의 주소를 표햔하기 위해서는 3개의 전선이, 16개의 주소를 표현하기 위해서는 4개의 전선이 필요하다.
만약 3번 주소에 데이터를 쓰고 싶다면 주소 전선에 11을 넣고 데이터 전선에 쓸 데이터 값을 흘려넣으면 메모리 3번에 데이터가 저장된다. 그럼 같은 전선에 데이터를 내보내고 들여보내도 되냐고, 어떻게 읽고 쓰기를 구분하냐고 묻는 분이 계실테다.
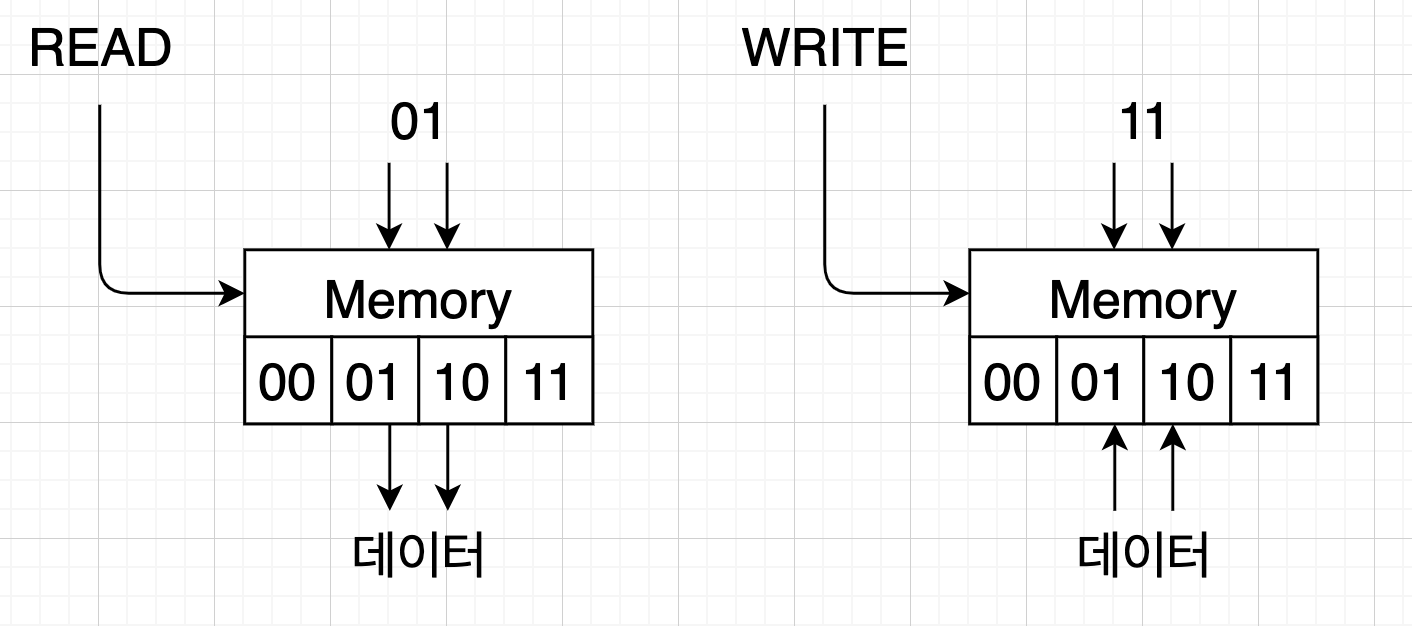
메모리에는 READ와 WRITE를 구분하는 컨트롤 전선이 별도로 있다. READ일때는 주소 전선에서 주소 값을 읽어서 데이터 전선으로 저장 값을 내보내고 WRITE일 경우에는 주소 전선에서 주소 값을 읽어서 데이터 전선으로 들어오는 값을 해당 주소에 저장한다.
32비트 컴퓨터? 64비트 컴퓨터?
앞서 설명한 "읽거나 쓸 주소를 입력받는 전선", "데이터를 내보내거나 쓰는데 사용하는 전선"을 부르는 이름이 있다. 전자는 "주소 버스(Address Bus)"라고 부르며, 후자는 "데이터 버스(Data Bus)"라고 한다. 주소 버스가 1개의 전선으로 구성되어 있다면 2개의 주소만, 2개의 전선으로 구성되어 있다면 4개의 주소만 구분할 수 있다. 즉 전선 n개로 2의 n승만큼의 주소를 표현할 수 있다.
2 ^ 1 = 2
2 ^ 2 = 4
...
2 ^ 32 = 4,294,967,296
주소 버스가 32개의 전선으로 구성되어 있다면 4,294,967,296개의 주소를 표현할 수 있는데 1개의 주소가 1바이트이기 때문에 4,294,967,296바이트, 즉 4GB의 주소를 구분할 수 있다. 이 제한 때문에 주소 버스가 32개의 전선으로 구성된 - 즉 흔히 말하는 32비트 컴퓨터의 최대 램 용량은 기본적으론 4GB가 한계였다. 인텔 80386이 연 32비트 시대는 AMD가 AMD64 아키텍쳐를 열면서 근본적인 4GB 메모리 제약을 벗어날 수 있었다. 최근에 나오는 64비트 컴퓨터는 이론상으로 18,446,744,073,709,551,616 바이트 혹은 17,179,869,184 기가바이트, 혹은 16엑사바이트의 메모리를 장착할 수 있어서 당분간은 메모리 제약을 고려하지 않아도 된다. 문제는 언제나 여러분의 지갑 사정이다.
데이터 버스는 역시 주소 버스와 마찬가지다. 주소 버스처럼 표현할 수 있는 주소의 수가 중요하지 않지만 도로와 같이 넓으면 넓을수록 한 번에 전송할 수 있는 데이터의 크기도 커진다. 이 데이터 버스를 통해 CPU와 메모리 사이에 끊임없이 데이터를 주고 받는다. CPU는 메모리에서 명령어와 데이터를 읽어들이며 필요할 때마다 메모리에 값을 저장하기도 한다.
CPU - 중앙처리장치
중앙처리장치, 혹은 프로세서(Processor) 혹은 CPU(Central Processing Unit)은 메모리에서 명령어를 읽어 그에 맞게 동작하는 장치다. 1장에서 설명한 튜링머신의 작동규칙표에 해당된다. 1장의 튜링머신의 동작에서 작동규칙표가 어떤 일을 했는지 기억해보자. 테이프에 쓰인 기호를 헤드를 통해서 읽고 기계의 현재 상태와 비교, 헤드를 통해 테이프에 특정 기호를 쓰고 헤드를 움직이는 역할이다. 이것이 바로 CPU의 역할이다.
먼저 CPU는 최대 3개의 피연산자를 사용하는 연산을 할 수 있다. 이 피연산자들의 정보는 CPU 내부에 있는 레지스터(Register)라고 하는 메모리에 저장되어 있다. CPU는 레지스터에 저장되어 있는 값으로만 연산을 수행하는 셈이다. 예를 들어 레지스터 B의 값을 A에 더해서 C에 넣으라거나 레지스터C에 1을 더하라던가 하는 일이 이와 같다. CPU는 메모리의 값을 직접적으로 불러와서 연산하지 않기 때문에 무조건 레지스터로 불러오거나 레지스터의 값을 메모리로 쓰는 명령어도 필요하다. 예를 들어 1번 메모리 값과 4번 메모리 값을 더해서 12번 메모리에 쓰고 싶다 한다면 다음과 같은 명령어가 필요하다.
- 메모리 1번의 값을 레지스터 A에 넣어라
- 메모리 4번의 값을 레지스터 B에 넣어라
- 레지스터 A와 레지스터 B의 값을 더해서 레지스터 C에 넣어라
- 메모리 12번에 레지스터C의 값을 써라
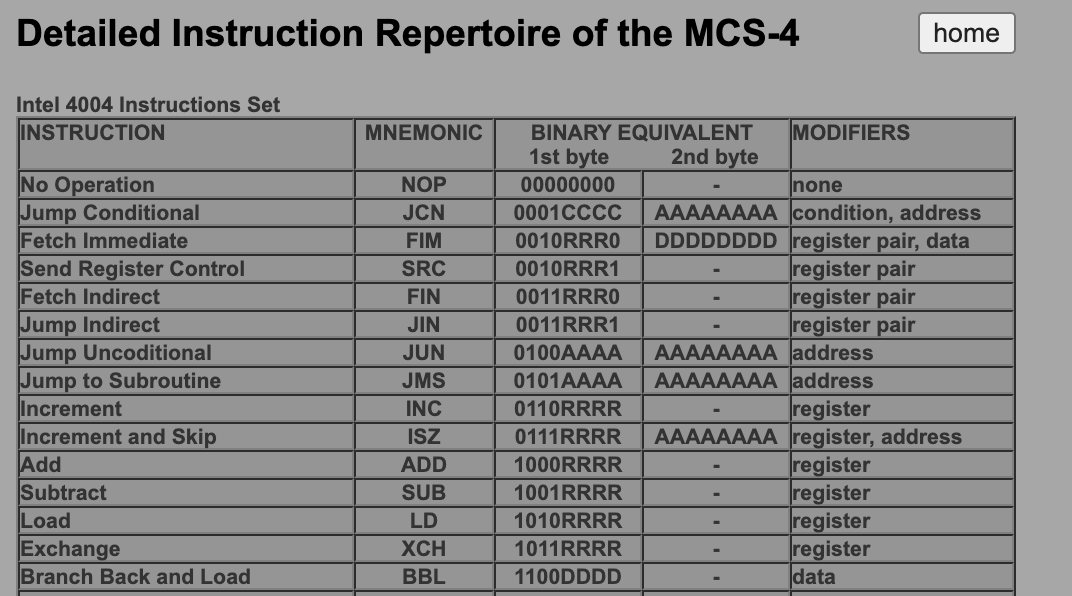
이렇게 더하고 읽고 쓰는 연산을 명령어(Instruction)이라 하며 이 모든 집합의 연산을 명령어 집합(Instruction Set)이라고 한다. 참고로 아래는 시조새급 CPU 인텔 4004의 명령어 집합이다.(참고: [http://e4004.szyc.org/iset.html])
CPU에 일 시키기
CPU에게 일을 시키려면, 즉 명령을 수행하려면 CPU가 알아먹을 수 있는 이진수로 작성해서 메모리에 저장해야 한다. 이 명령어 형식은 CPU마다, 아키텍쳐마다 다르다. x86 아키텍쳐 책만 읽어서 ARM에도 해당되는지는 확실치 않지만 컴퓨터 구조 책마다 동일한 설명을 하는것 보니 이 명령어 형태는 비슷할 걸로 예상한다. 명령어 형태는 초반 n비트는 Opcode - 한국어로 '명령 코드' -라 불리는 숫자가 있고 그 뒤로는 피연산자(Operands) 정보가 있다. 위에서 예시로 든 메모리 값을 불러서 더하고 그걸 다시 메모리에 쓰는 명령어를 기계어로 표현해보겠다.
일단 x86 아키텍쳐 말고 우리 만의 CPU k2020의 OpCode를 정의해보자.
| OpCode | MNEMONICS | Operand1 | Operand2 | Operand3 | 설명 |
|---|---|---|---|---|---|
| 1 | ADD | RRRR | DDDD | CCCC | 레지스터 주소 DDDD의 값과 레지스터 CCCC의 값을 더해서 레지스터 RRRR에 넣어라 |
| 2 | STORE | MMMM | RRRR | 레지스터 RRRR의 값을 메모리 주소 MMMM에 넣어라 | |
| 3 | LOAD | MMMM | RRRR | 메모리주소 MMMM의 값을 읽어서 레지스터 RRRR에 넣어라 |
OpCode, Operand 1, 2, 3은 각각 편의상 4비트라 하고 레지스터 A, B, C의 주소를 각각 1, 2, 3이라 가정한다.
그리고 앞에 말했던 내용을 CPU에게 일을 시켜보겠다.
- 메모리 1번의 값을 레지스터 A에 넣어라 (LOAD 0001 0001) -> 0011 0001 0001
- 메모리 4번의 값을 레지스터 B에 넣어라 (LOAD 0100 0010) -> 0011 0100 0010
- 레지스터 A와 레지스터 B의 값을 더해서 레지스터 C에 넣어라 (ADD 0101 0001 0010) -> 0001 0101 0001 0010
- 메모리 12번에 레지스터C의 값을 써라 (STORE 1100 0011) -> 0010 1100 0011
이 명령의 집합을 '프로그램'이라고 한다. 여러분들이 Javascript, Python, C/C++, Java 등으로 코딩을 하는 행위는 곧 CPU에게 명령을 내리기 위한 명령어를 짜는 행위다. 여러분의 코드를 명령어의 집합으로 바꿔주는게 컴파일러(Compiler)라고 하며, 이 명령어의 집합을 메모리에 올려서 CPU에게 일을 시키는게 운영체제다.
컴파일러와 OS도 보통 학과 3학년 이상에 배우는 과목으로, 컴퓨터 과학의 중요 과목 중 하나다. 이 두 개는 이번 장 뒤에 간략히 다루도록 한다.
추가 공부
본 내용은 컴퓨터 구조의 CPU에 나오는 내용입니다. 명령어 형식에도 여러 종류가 있습니다. k2020 아키텍쳐의 경우에는 2-address instruction 혹은 3-address instruction이라고 고정했지만 실제로는 0-address 도 있으며, 명령어 addressing 방식에 대한 설명, 파이프라인, 제어장치, 동기화 클럭 등 많은 부분을 생략했기 때문에 좀 더 상세한 내용을 알고싶으신 분은 컴퓨터 구조(Computer Architecture) 책을 읽어보시면 도움이 많이 됩니다.
컴퓨터가 데이터를 다루는 방법
진법(numeral system)
사람은 10진법을 사용한다. 0부터 9까지의 숫자를 사용해서 무한대의 숫자를 표현한다. 반면 컴퓨터는 2진법(binary)을 사용한다. 높은 전압이 걸리면 1, 낮은 전압이 걸리면 0을 표현하며 0과 1로 무한대의 숫자를 표현하기 때문이다. 예를 들어보자.
5는 이진수로 101
27은 이진수로 11011
967은 이진수로 1111000111
10진수를 2수로 변환하는건 쉽다. 어떤 정수가 있다면 계속해서 2로 나눠주자. 예를 들어 10진수 27을 2진수로 변환하고 싶다면
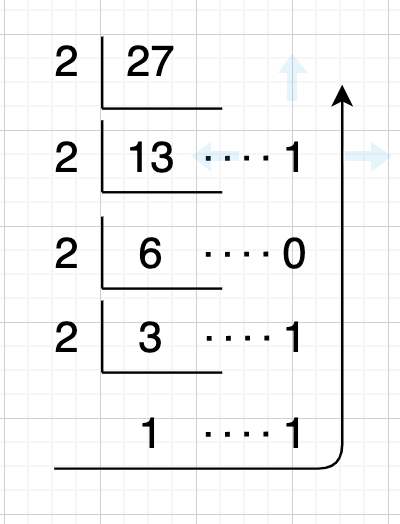
여기서 나오는 나머지를 아래에서 위로 모으면 11101이 된다. 소수는 이 반대로 하면 된다. 예를 들어 0.3을 2진수로 변환하고 싶다면 2를 계속 곱해서 정수로 자리 올림이 나오면 1 아니면 0으로 기록하면 된다.
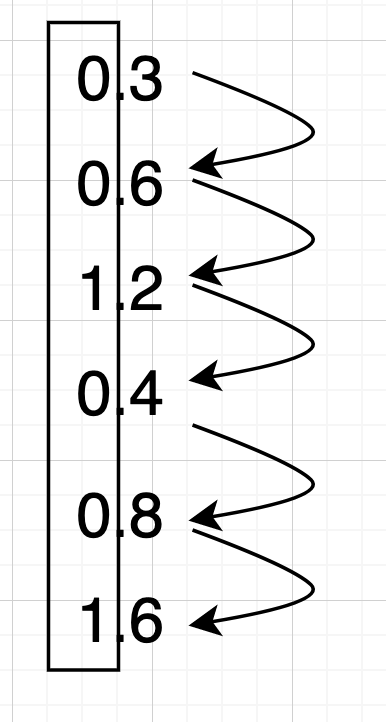
위에서부터 네모 부분을 차례대로 읽으면 001001이 되는데 직접 나눠보시면 알겠지만 끝자리가 계속 6, 2, 4, 8이 이어지면서 끝이 없는 소수, 즉 무한소수가 나온다. 10진수에서는 그냥 0.3으로 끝나는 유한소수지만 2진수에서는 무한소수가 된다. 비단 0.3뿐만 아니라 10진수에서는 딱 떨어지는 많은 유한소수가 이진수에서는 끝이 없는 무한소수가 된다. 따라서 컴퓨터는 최대한 0.3에 근사한 값을 표현할 수 있을 뿐이지 슬프게도 정확하게 0.3 이라고 표현할 수 없다.
그래서 표기할때 자리수를 적당히 잘 제한해서 표기해야지 아니면 아래와 같은 사태가 벌어지기도 한다.(실제 사례...)
16진수와 8진수
이진수는 컴퓨터가 사용하는 진법이기 때문에 숫자가 늘어나면 자릿수가 급격하게 늘어나고 무엇보다 사람이 알아보기 힘들다. 101111010011100101이 10진수로 몇 인지 내가 알게 뭐냔말이다. 그래서 사람이 볼 때는 10진법으로 바꾸기도 하지만 때에 따라서는 8진법(octal)이나 16진법(hexa-decimal)을 사용하기도 한다. 요즘은 혼동의 우려때문에 8진수를 잘 안쓰긴 하지만 컴퓨터에서 왜 2진법 외에 8진법과 16진법이 많이 사용되는 이유는 변환의 편의성 때문이다. 2진수를 3개씩 묶으면 8진수가 되고 2진수를 4개씩 묶으면 16진수가 된다.
예를 들어 위에서 10진수 967을 8진수로 내자면 이진수 1111000111을 3개씩 묶는다. 앞에서부터 묶는게 아니라 뒤부터 묶어야 한다. 8진수는 0~7까지 사용하기 때문에 1707이 된다.
1 111 000 111
1 7 0 7
16진수는 4개씩 묶는다. 참고로 16진수는 0~9와 A(10), B(11), C(12), D(13), E(14), F(15)을 사용한다. 괄호 안의 숫자는 10진수 값이다.
11 1100 0111
3 C 7
따라서 1111000111는 16진수로 3C7이 된다. 보통 16진수는 0x를 붙여서 표기하기 때문에 위 숫자는 0x3C7이 되며 8진수는 01707처럼 앞에 0을 붙여서 표기한다. 8진수는 평소에 보기 힘들지만 16진법은 CSS에서 색상 표현할때 자주 마주할 수 있다. RGB형태로 색상을 표현할때 순수한 파란색은 Red가 0, Green이 0, Blue가 255이기 때문에 #0000FF로 표현한다. 10진수 255는 16진수 FF이기 때문이다.
정수 표현하기
수학시간에 정수에 대해서 배웠을 것이다. 정수는 자연수와 0 그리고 음의 정수의 집합이다. 컴퓨터 세계에서도 이 의미는 동일하지만, 컴퓨터의 한계 때문에 표현 방법과 범위가 약간 다르다. 여기서는 부호 있는 정수와 부호 없는 정수로 나눠서 설명하려고 신나게 쓰다가 생각해보니 이 글의 독자들은 대부분 이 내용을 알 필요가 없다. 여기서 설명하는 내용은 대부분 C/C++, Go, Rust 와 같이 결과물이 기계어로 된 실행 파일을 생성하는 언어를 사용할 때 알아야 할 내용이지 Python, C#, Javascript, Java와 같은 인터프리터나 VM상에서 동작하는 언어에서는 사실 이 내용을 반드시 알아야 할 필요가 없다. 이 책의 독자들은 대부분 후자이기 때문에 설명을 생략한다.
참고로 이 글에서 원래 다룰려는 내용은 기호를 표현할때 사용하는 MSB(Most Significant Bit), 연산을 위한 2의 보수 체계, Overflow/Underflow 및 Wrap-up 현상이 있다. 이는 나중에 기회될 때 중간중간에 언급할 기회가 있으리라 믿는다.
실수 표현하기
정수가 아닌 소수점이 있는 실수는 컴퓨터 입장에서는 표현하기가 정수보다 난이도가 훨씬 높다. 정수와는 다르게 값을 있는 그대로 저장하지 않고 약간은 특별한 형태로 데이터를 저장하고 표현하는 2가지 방법이 있다.
고정 소수점
말 그대로 소수점이 고정되어 있다. 예를 들어 13.74를 표현한다고 해보자. 이를 정수부 13과 소수부 .74로 나눈다. 이를 다시 2진수로 변환하면 정수부는 1011, 소수부는 10111101.... 이다. 고정 소수점 표현(fixed-point representation) 방식은 소수점을 특정 비트 위치로 고정하고 이 값을 특정 비트 앞을 정수부, 특정 비트 뒤를 소수부로 나눠서 표현한다는 점이다. 예를 들어 16비트(2바이트) 구조에서 표현한다면 앞 8비트를 정수부, 뒤 8비트를 소수부로 나누어서 표현하고 앞에서 예를 든 13.74는 아래처럼 표현할 수 있다.
0.101111010111000010

고정 소수점 표현은 나름 숫자 표현이 간단하고 연산속도도 빠르지만, 표현할 수 있는 숫자의 범위가 제한적이라서 거의 사용하지 않는다고 봐도 무방하다. 그냥 교양으로 이런 방식이 있구나 정도로 알아두시면 된다.
부동 소수점
부동은 '부동자세'라는 말처럼 움직이지 않는다의 부동(不動)이 아니라 떠 다닌다는 부동(浮動)이다. 영어의 floating point 를 그대로 가져온 말이다. 뇌피셜로 아마 일본에서 먼저 들어온 말인듯하다. 고정소수점의 예제 숫자 0.74를 부동 소수점으로 어떻게 표현하는지 알아보자.
일단 컴퓨터에 저장을 위해 0.74를 2진수로 변환해보자. 0.10111101....이다. 이를 정수부에 1이 오도록 소수점을 옮겨보자. 2의 -1승을 곱하면 1.0111101...이 된다. 이 값을 다르게 표현하면 1.0111101 x 2^-1 으로 표현할 수 있으며 이렇게 표현하는 방식을 정규화된 표기법(Normalized Notation)이라고 한다. 정규화된 표기법으로 변환한 상태에서 가수(fration/mantissa)와 지수(exponent), 그리고 부호를 나눠서 표기하는게 부동소수점 표현의 요지다. 참고로 1.0111101은 가수라고 하며 2^-1에서 -1을 지수라고 한다.
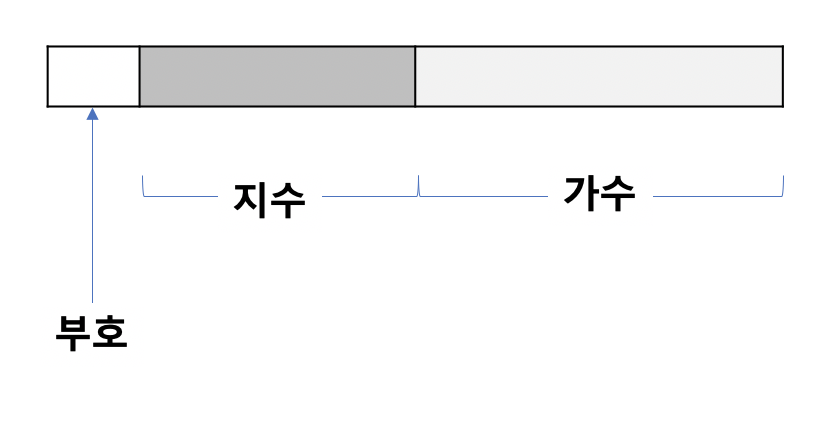
8비트 공간에서 부동소수점을 표현해보자. 부호를 표기하는 1비트가 필요하다. 0이면 양수 1이면 음수다. 그 다음 3비트는 지수를 표현하기 위한 공간, 남는 4비트는 가수를 표기하기 위한 공간으로 할당한다. 아까 2진수로 표현한 0.74를 8비트 공간에 표현하면 아래와 같다.
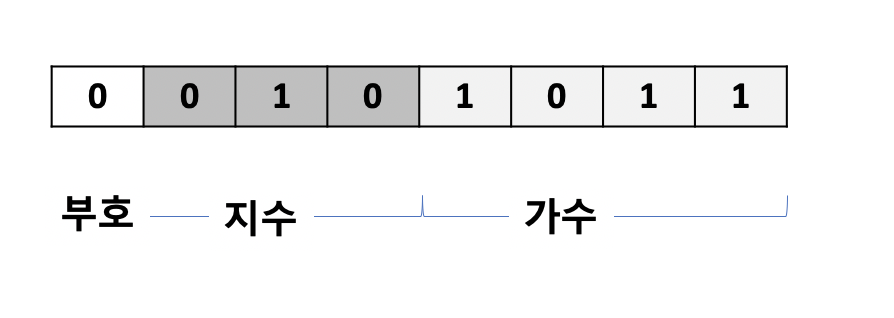
위 값을
자세히 보자...
자세히 보자....
자세히 보자.....
뭔가 이상한걸 못느끼는가?
초과 표현
아까 지수가 -1이니까 지수는 1이 오는게 아닌가요? 라는 질문이 있으면 제대로 짚었다. 지수를 표현할때는 보통 초과표현이라는 방법을 사용하는데 n개의 비트가 지수표현에 할당되었을때 -(2^(n-1) - 1)값을 기준값 0으로 잡고 표현하는 방법이다. 위의 예제는 지수 표현에 3비트를 잡았으니 -(2^2 -1) = -3을 0으로 잡는다. 위 공식에 의하면 지수가 -3이면 000, -2이면 001 -1이면 010, 0이면 011, 1이면 100, 2이면 101, 3이면 110, 4이면 111이 된다.
이렇게 표현하면 가장 큰 장점은 값의 비교가 굉장히 간단해진다. 단순히 지수만 비교하면 큰 값과 작은 값을 바로 구분할 수 있다.
실세계 사용
아까 예로 들었던 수 0.74를 보자. 이를 8비트 부동소수점 구조에 맞춰넣으면 가수부는 4비트이기 때문에 4자리 이후는 버림 처리되서 1.0111 x 2^-1이 된다. 정규화된 표기법의 역순으로 처리하면 0.10111이 된다. 이를 다시 10진수로 변경해보자.
= 0 * 2^0 + (1 * 2^-1) + (0 * 2^-2) + (1 * 2^-3) + (1 * 2^-4)+ (1 * 2^-5)
= 0 + 1/2 + 0 + 1/8 + 1/16
= 0 + 0.5 + 0 + 0.125 + 0.0625
= 0.6875
원래 값이 0.74인데 저장하는 값은 0.6875라니!! 어떻게 이런 일이 일어나는 걸까?
이는 가수 정보를 저장하는 공간이 4비트밖에 없어서 발생한 일이다. 예를 들어 가수를 저장하는 공간이 4비트가 아니라 8비트라고 가정해보자. 0.74는 2진수로 0.10111101011100001010001111...인데 이를 정규화된 표기법으로 표기하되 가수부를 4비트가 아닌 8비트로 늘린다. 그럼 1.01111010 x 2^-1이 된다. 이를 다시 10진수로 바꿔보자
0 * 2^0 + (1 * 2^-1) + (0 * 2^-2) + (1 * 2^-3) + (1 * 2^-4) + (1 * 2^-5) + (1 * 2^-6)+ (0 * 2^-7)+ (1 * 2^-8) + (0 * 2^-9)
= 0 + 1/2 + 0 + 1/8 + 1/16 + 1/32 + 1/64 + 0 + 1/256 + 0
= 0 + 0.5 + 0 + 0.125 + 0.0625 + 0.03125 + 0.015625 + 0 + 0.00390625 + 0
= 0.73828125
짠! 가수부를 2배 늘렸는데 아까의 0.6875보다 훨씬 0.74에 근접하게 표현할 수 있다. 부동 소수점은 지수를 저장하는 공간이 크면 더 많은 수를 표현할 수 있고 가수를 저장하는 공간이 크면 정확도가 높아진다.
누군 가수부가 10비트 누군 20비트 이러면 혼란이 오기 때문에 IEEE라는 국제기구에서 컴퓨터에서 부동소수점을 표현하기 위한 표준을 제정했다. IEEE743라는 표준이 그것인데, 여기서는 32비트, 64비트 부동소수점에 대한 정의가 있다. 이 문서에서 정의하는 32비트 부동소수점 표현을 보면 맨 첫 비트는 부호로, 그 다음 8비트는 지수 표현에, 나머지 23비트는 가수를 표현한다. 64비트 부동소수점 표현을 보면 맨 첫 비트는 부호, 그 다음 11비트는 지수 표현에, 나머지 52비트는 가수를 표현하는데 사용한다.
32비트 부동소수점의 정밀도를 영어로 single precision, 한글로는 단정도라고 하며, 64비트 부동소수점의 정밀도를 영어로 double precision이라 하며 한글로는 배정도라고 한다. 파이썬에 float, Javascript의 number 형태가 모두 double precision이다. 프로그래밍 언어 중에서 이를 구분하는 언어도 많다. C/C++, Java의 float, Go의 float32, Rust의 f32는 single precision, C/C++, Java의 double, Go의 float64, Rust의 f64는 double precision을 나타낸다.
과거에는 single/double precision간의 CPU 연산 속도의 차이가 있어서 두 개를 구분해서 사용하기도 했지만 최근 CPU는 single/double precision간의 연산 속도의 차이가 거의 없기 때문에 기본 부동소수점 표현을 double precision으로 처리하는 언어도 있다. 대표적인 언어가 Rust이다.
주의점
부동소수점을 다룰때 반드시 주의해야 할 점이 있다. 두 부동 소수점을 직접 비교하지 말라는 점이다.
아래 코드를 보자
let f1 = 1000000.1 + 0.2;
let f2 = 1000000.3;
if (f1 === f2) {
// 멋진 코드
}
여러분의 멋진 코드가 실행 될까 안될까? 직관적으로 나의 멋진 코드가 실행되어야 마땅하나 실제로는 f1 === f2는 false가 나온다. 1000000.1 + 0.2값은 1000000.299999999...가 나오기 때문이다. 컴퓨터 구조의 한계때문에 발생하는 일이라 비단 자바스크립트 외에 다른 언어도 모두 같은 문제를 안고 있다.
부동소수점을 잘못 쓰면 아래와 같은 일도 겪을 수 있다. (출처: https://kldp.org/node/98110)
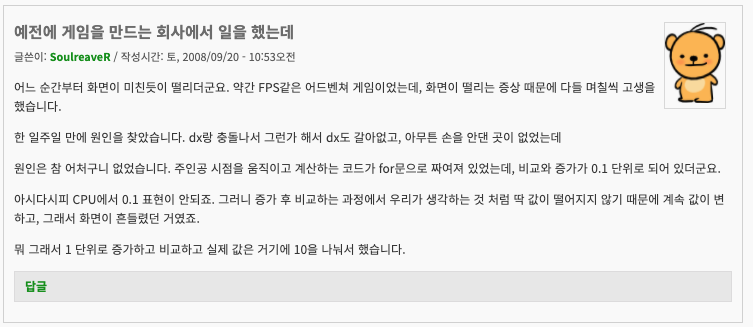
코드는 대충 아래와 같이 짰을거라 생각한다. C언어는 오랜만이라 문법이 맞는지 모르겠으나..
for (float i = 0.0; i < 100; i += 0.1 ) {
}
위 코드는 직접적으로 if를 사용하지는 않았지만, 반복문 for안에서 부동소수점 증가 연산과 비교 연산을 수행하고 있다. 참고로 C/C++의 신뢰성을 위한 코드 규약인 MISRA에서는 부동 소수점간의 동등 비교를 하지 말라고 되어 있다.
MISRA C:2004, 13.3 - Floating-point expressions shall not be tested for equality or inequality.
MISRA C++:2008, 6-2-2 - Floating-point expressions shall not be directly or indirectly tested for equality or inequality
컴파일러
CPU에 일 시키기
CPU에게 일을 시키기 위해서는 CPU가 이해할 수 있는 0001 0000 0100 0111 이런 명령어를 입력해야 한다. 하지만 매우 간단한 프로그램이라면 모를까 WO*, LO* 같은 게임부터 포토*, 웹 브라우저같은 방대하고 화려한 프로그램에는 수 억, 수 십억개의 명령어가 필요한데 어느 누가 0001 0000 0100 0111 이런 명령어를 수 억개나 쓰고 싶겠는가. 이렇게 컴퓨터에게 일을 쉽게 시키기 위해서는 인간의 언어와 가까운, 최소한 인간이 이해할 수 있는 프로그래밍 방식이 필요했고 이에 발맞춰 프로그래밍 언어가 생겼다.
필요성이 명확했기에 프로그래밍 언어는 생각보다 굉장히 초창기부터 등장했다. 수식 계산에 초점을 맞춘 포트란(FORTRAN)이라는 언어는 이미 1950년대 말에 처음으로 탄생했을 정도였다. 초창기 포트란 프로그램은 아래와 같이 생겼다. 아래 예제는 포트란II로 작성된 프로그램으로, 개인적으로 포트란은 잘 모르기 때문에 위키북스의 예제를 들고왔다.
C AREA OF A TRIANGLE - HERON'S FORMULA
C INPUT - CARD READER UNIT 5, INTEGER INPUT
C OUTPUT -
C INTEGER VARIABLES START WITH I,J,K,L,M OR N
READ(5,501) IA,IB,IC
501 FORMAT(3I5)
IF(IA.EQ.0 .OR. IB.EQ.0 .OR. IC.EQ.0) STOP 1
S = (IA + IB + IC) / 2.0
AREA = SQRT( S * (S - IA) * (S - IB) * (S - IC) )
WRITE(6,601) IA,IB,IC,AREA
601 FORMAT(4H A= ,I5,5H B= ,I5,5H C= ,I5,8H AREA= ,F10.2,
$13H SQUARE UNITS)
STOP
END
1001 0000 0101 1111 혹은 MOV $1, $2 이런 명령어보다 훨씬 인간이 이해하기 쉽다. 아니 그럼 이 코드는 CPU가 이해할 수 없을텐데 어떻게 CPU에게 일을 시키나요? 그래서 프로그래밍 언어와 뗄레야 뗄 수 없는 영혼의 단짝을 이루는게 바로 컴파일러(compiler)이다. 컴파일러는 여러분의 코드를 CPU가 알아먹을 수 있도록 1001 0000 0101 1111같은 명령어의 집합으로 바꿔주는 프로그램이다. 현대의 컴파일러는 C/C++과 같은 프로그래밍 언어를 기계어로 번역해주는 일을 한다고 볼 수 있다. 참고로 CPU가 별도의 컴파일러 없이 알아들을 수 있는 1001 0000 0101 1111같은 명령어도 프로그래밍 언어의 범주에 속하고, 이를 기계어(Machine Code)라고 한다.
파이썬은 컴파일러가 없는데요? 이 얘기는 나중에 설명하고...
컴파일러의 구조
최신 컴파일러는 보통 2단계 혹은 3단계로 구성되어 있다. 프론트 엔드(Front end), 미들 엔드(Middle End), 백엔드(Back End)에 대한 내용을 신나게 쓰다가 너무 깊이 들어가는 듯 하여 다 지우고 간단하게만 언급하고 넘어간다. 자세한건 나중에 다시 별도의 장으로 만들어서 설명하면 좋겠다. (희망사항)
프론트엔드는
- 소스 코드를 단어 별로 잘라서 이 단어가 무엇인지 딱지를 붙이고(Lexical Analysis)
- 구문 트리(Syntax Tree)라는 것을 만든다. (Syntax Analysis)
- 이 구문 트리로 의미를 해석한다. (Semantic Analysis)
이 과정을 통해 문법에 맞지 않는 소스 코드에 에러나 경고를 날리고 에러가 없으면 추상 구문 트리(Abstract Syntax Tree)를 만들어 내서 미들 엔드에 넘긴다.
미들엔드는
- 추상 구문 트리로 중간 표현(IR, Intermediate Representation) 혹은 중간 코드(IC, Intermediate Code)라고 불리는 데이터로 변환한다.
- 이 과정에서 최적화를 실행한다. 안쓰는 코드를 날려버린다거나 절대 실행되지 않을 코드, 루프 연산 최적화 등이 이 과정에서 발생한다.
미들엔드의 최종 결과물은 최적화된 IR이다.
컴파일러의 최적화를 맛보기로 보여주면,
int square(int num, int t) {
int k = 0;
if (k == 1) {
int a = t + 1;
return a;
}
return num * num;
}
이런 C++ 코드가 있다. k값이 0이기 때문에 if (k == 1) 블럭 안의 문장은 수행되지 않는다. Microsoft의 C++ 컴파일러인 x64용 MSVC 19.27 버전에서 컴파일을 하면 아래의 어셈블리어로 컴파일한다. 참고로 어셈블리어는 기계어와 1:1로 대응되지만 mov $1, $2와 같이 사람이 조금 더 보기 편하게 볼 수 있는 프로그래밍언어다.
k$ = 0
a$1 = 4
num$ = 32
t$ = 40
int square(int,int) PROC ; square
$LN4:
mov DWORD PTR [rsp+16], edx
mov DWORD PTR [rsp+8], ecx
sub rsp, 24
mov DWORD PTR k$[rsp], 0
cmp DWORD PTR k$[rsp], 1
jne SHORT $LN2@square
mov eax, DWORD PTR t$[rsp]
inc eax
mov DWORD PTR a$1[rsp], eax
mov eax, DWORD PTR a$1[rsp]
jmp SHORT $LN1@square
$LN2@square:
mov eax, DWORD PTR num$[rsp]
imul eax, DWORD PTR num$[rsp]
$LN1@square:
add rsp, 24
ret 0
int square(int,int) ENDP
뭔진 모르겠지만 뭔가 기계어가 많다. 똑같은 코드 그대로 최적화 옵션을 켜고 (/Ox) 컴파일을 해보면
num$ = 8
t$ = 16
int square(int,int) PROC ; square
imul ecx, ecx
mov eax, ecx
ret 0
int square(int,int) ENDP ; square
짜잔~! 변환된 기계어 코드가 극적으로 줄어든 것을 확인할 수 있다. 컴파일러 내부적으로 절대 도달할 수 없는 경로(Unreachable Code)인 if (k == 1) 블럭을 통째로 날려버리고 더 나아가 사용하지 않는 코드(Unused Code)인 int k = 0도 없애버린걸 알 수 있다.
백엔드는
- 이 최적화된 IR로 대상 아키텍쳐에 최적화된 기계어를 생성한다. 2장 2절에서도 말했듯이 CPU마다 알아듣는 명령어가 다르기 때문에 각 CPU(ARM이라던가 Intel이라던가 ..)에 맞는 기계어를 생성한다. 엄밀하게 말해서는 컴파일러는 목적코드(Object Code)라는 걸 생성하고 링커(Linker)라는 프로그램이 이 목적 코드를 합쳐서 실행 가능한 코드를 만든다.
왜 윈도우 프로그램이 MacOS에서 동작하지 않나요?
유명한 오픈소스 프로젝트 중에 파일질라(File-zilla)라는 FTP 프로그램이 있다. 이 프로그램을 다운로드 받기 위해 다운로드 페이지로 가보면 Mac OS X, Windows 64bit, Windows 32bit, Linux 32bit, Linux 64bit 용 다운로드 항목이 다르다.
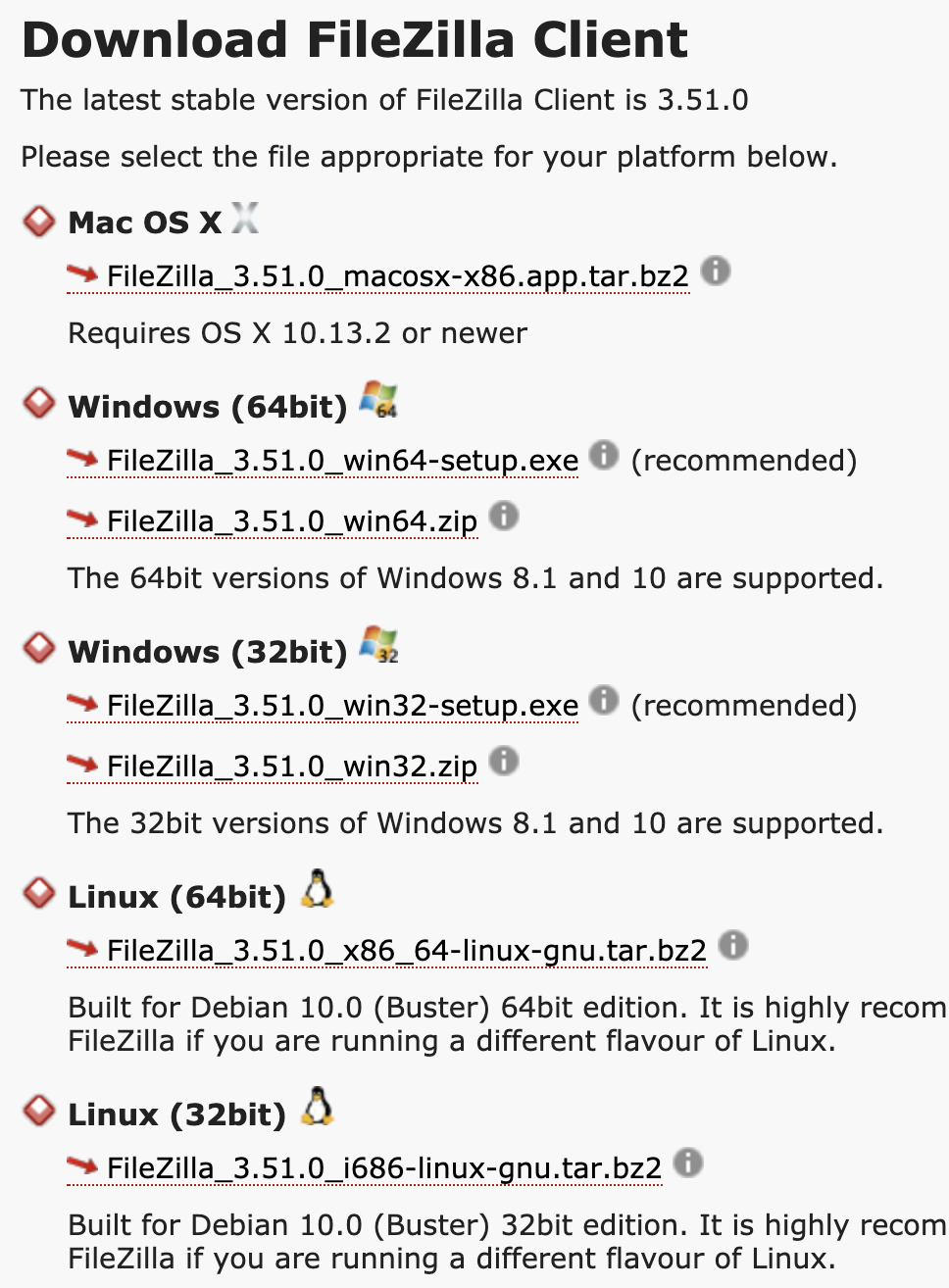
아니 어차피 다 같은 Intel CPU에서 동작하는데 왜 패키지가 다른가요? 여태까지 배운걸로는 같은 CPU에서 동작하니까 명령어 코드도 같고 리눅스건 윈도우건 나눌 필요가 없지 않나요 물어볼 수 있겠다. 반은 맞고 반은 틀리다.
컴퓨터는 CPU만 있는게 아니다. 물론 CPU없는 컴퓨터는 뇌 없는 인간과 같지만 인간은 뇌만으로 이뤄진건 아니고 눈, 코, 입, 귀, 다리, 팔, 내장이 조화를 이뤄야 진정한 인간이 된다. 컴퓨터는 모니터도 있어야되고 SSD도 있어야 되고 키보드, 마우스, 그래픽카드, 무선랜카드 등등이 있어야 비로소 컴퓨터가 된다. 이런 주변기기들을 제어해야 하는데 하나의 프로그램에서 수 많은 무선랜 카드를 제어하는 프로그램을 넣고 수 많은 키보드를 제어하는 프로그램을 넣는건 불가능하다. 이 때문에 운영체제(Operating System)가 존재하는 이유다. 운영체제는 프로그램을 대신해서 주변장치를 제어할 수 있도록 해준다. 프로그램은 운영체제에 그저 시스템 콜(System Call)이라는 특별한 명령어를 보내면 주변 기기를 제어할 수 있다.
문제는 시스템 콜이 운영체제 마다 다르다. 제목대로 윈도우의 시스템 콜은 Mac OS의 시스템 콜과 매우 다르다. 따라서 윈도우 프로그램은 Mac에서 동작하지 않는다. (Executable Format이 다르기도 하지만...) 그렇기 때문에 모든 프로그램은 파일질라 다운로드 페이지처럼 특정 CPU와 더불어 특정 운영체제용으로 컴파일해서 배포된다.
스크립트 언어
모든 프로그래밍 언어가 컴파일이 필요한 건 아니다. 이른바 스크립트 언어라 불리는 프로그래밍 언어는 컴파일 없이 바로 실행이 가능하다. 대표적인 언어로는 자바스크립트, 파이썬, PHP 등이 있다. 허나 OS와 스크립트 언어 사이에서 누군가는 소스코드를 기계어로 바꿔줘야 실행이 가능한데, 그 '누군가'가 바로 인터프리터(interpreter)라고 불리는 프로그램이다.
컴파일된 코드는 마치 사전에 번역한 문서와 같다면 인터프리터는 마치 통역가와 같은 존재다. 한쿡인이 독일인에게 자신의 의사를 전달하려 할때 통역가는 한국인이 말 할때마다 독일어로 바꿔서 말해준다. 인터프리터도 다르지 않다. 컴파일된 코드는 이미 CPU/OS에 맞게 모두 번역되어 있는 상태, 즉 컴파일 결과로 목적 플랫폼에 맞는 기계어로 만들어져 있어서 CPU에서 바로 실행할 수 있지만 스크립트 언어는 실행 시점에 해당 CPU/OS에서 해석 가능한 코드로 번역하기 때문이다.
컴파일이 필요한 언어와 스크립트 언어는 각각 장단점이 굉장히 뚜렷하다. 스크립트 언어는 반드시 동작시킬 플랫폼에 맞는 인터프리터가 필요하지만, 컴파일이 필요한 언어는 그렇지 않다. 반면 스크립트 언어는 컴파일된 코드에 비해 매우매우 느리다. 이를 뒤집어 보면 스크립트 언어는 컴파일이 필요없지만 컴파일이 필요한 코드는 반드시 컴파일 과정을 거쳐야하는데, 규모가 크면 클 수록 컴파일에 걸리는 시간(보통 컴파일 시간 혹은 컴파일 타임이라고 한다)이 무시못할 정도로 커진다. 간단한 작업의 경우에는 스크립트 언어가 훨씬 강점이 많다.
JIT(Just-in-time) 컴파일러
앞서 설명한 대로 컴퓨터에게 일을 시키기 위해서는 미리 코드를 컴파일 해놓거나 인터프리터를 이용해서 실행 중 그때그때 기계어 코드를 생성해서 실행하는 방법이 있다. JIT 컴파일러는 이 두 가지 방식을 섞어놓은 방식이라고 생각하면 된다.
이 JIT 컴파일러를 사용하는 대표적인 언어인 자바를 예시로 들면서 설명하겠다. 내가 만든 짱 멋진 스프링으로 만든 웹서버를 리눅스 서버에 올려서 서비스를 한다고 가정해보겠다. 맥OS용 인텔리J에서 열심히 코드를 짜서 빌드를 하면 내부적으로 javac라는 컴파일러가 자바 코드를 바이트코드(Bytecode)라는 코드로 변환한다.
이를 리눅스 서버로 올려서 실행하면 해당 바이트 코드는 리눅스용 JVM(Java Virtual Machine)에서 읽어서, 필요할 때마다 바이트코드를 JIT 컴파일러에서 리눅스에 맞는 기계어 코드로 변환해서 실행한다. Just-in-time은 그때그때마다 적기적소라는 의미를 담고 있다.
아니 그럼 인터프리터를 쓰는 스크립트 언어와 뭐가 달라요?
굉장히 좋은 딥 태클이다. 크게 보자면 다른건 없는데 자세히 보면 다르다. 일단 다른 스크립트 언어보다 훨씬 빠르다. 그 이유는 바로 바이트코드에 있다.
앞서 최신 컴파일러는 프론트엔드 - 미들엔드 - 백엔드로 구성되어 있다는 점을 설명했다. 자바의 전략도 이와 유사하다. javac를 통해 바이트코드로 컴파일하는 단계는 컴파일러의 프론트엔드 - 미들엔드와 같다. 바이트코드로 변환하는 단계에서 코드 최적화가 수행되기 때문이다. 이 바이트코드는 컴파일러 미들엔드의 산출물인 중간 표현(IR)과 일면 동일하다고 볼 수 있다. 반면 일반적인 스크립트 언어는 미들엔드에서 수행하는 최적화 과정이 없다.
이것만으로는 자바가 다른 스크립트 언어보다 훨씬 빠르다는 점을 뒷받침하기엔 좀 약한데, 이 부분은 바이트코드와 JVM안에 내장된 JIT 컴파일러의 활약으로 커버할 수 있다. 먼저 바이트코드는 기계어로 빠르게 변환을 목적으로 설계되었기 때문에 기계어로 컴파일이 빠르며, 이 바이트코드를 기계어로 컴파일하는 JIT 컴파일러의 캐싱 전략 때문에 한층 더 빠르다. 자주 사용하는 물건을 가까이 놓는 것처럼 자주 사용하는 기계어를 캐시에 저장해서 바이트코드를 기계어로 컴파일 하는 횟수를 줄이기 때문이다.
컴파일러의 종류
위에서 소스 코드를 실행 가능한 기계어로 번역해주는 일을 하는게 컴파일러라고 썼지만, 사실 컴파일러의 범주는 꽤나 넓다. 타입스크립트를 자바스크립트로 바꿔주는 tsc도 넓게보면 컴파일러로 분류할 수 있으며 자바나 파이썬처럼 바이트코드로 만들어주는 프로그램도 컴파일러다. 또한 JIT 컴파일러 역시 컴파일러의 일종이다.
마치며
과거 소스 코드의 문제점을 실행해보지 않고 검사해주는 정적코드 분석기(Static Code Analysis)를 만들었던 적이 있어서 컴파일러 이야기가 매우 반가웠다. 하지만 신나게 적다보면 독자들이 이해하기 힘들 수 있으니 처음부터 마음을 다잡고 굉장히 기초적인 내용만 적었다. 컴파일러는 보통 컴퓨터공학 3~4학년이 수강하는 과목이다. 그 말인 즉슨 1~3학년때 배운 수학, 컴퓨터구조, 자료구조, 알고리즘, 운영체제, 프로그래밍 언어론 등등의 모든 컴퓨터 공학을 집대성한 분야이기 때문에 내용도 상당히 심오하고 구현은 상당히 어렵다. 나중에 별도의 장(chapter)에서 다룰 수 있기를 바란다!
네트워크/인터넷
이 장에서는 네트워크 기본, TCP/IP, 인터넷 동작원리에 대해서 적었습니다. 원래는 프로그래밍 언어론에 대해서 먼저 적을 계획이었으나, 회사 주니어 개발자 들이 모두 웹 개발자이기 때문에 네트워크를 먼저 적었습니다. 사실 네트워크는 학부때 제가 크게 관심있던 과목이 아니었습니다. 과목 자체가 프로그래밍 실습보다는 이론 수업이 많아서 크게 애정을 가지고 듣지 않았더니 지금 전공책을 뒤적이면서 고생하네요.
다만 저는 프로그래머이며 네트워크 구성/하드웨어나 현재 우리나라 ISP 현황에 대해서 밝은 편인 아니라서, 자료는 나름 찾아서 적긴 했지만 틀릴 가능성이 많습니다. 많은 지적 부탁드립니다.
또한 네트워크에 대해서 그냥 학부생 정도의 지식밖에 없기 때문에 어떻게 글의 흐름을 이어 나가야할지 아직 확신이 서지 않은 상태라 글의 순서나 내용이 변경될 가능성이 큽니다. 특히 TCP/IP의 IP 설명과 라우팅 설명을 매끄럽게 전개하려다보니 변경 가능성이 큽니다. 이 부분을 염두하고 읽어주시면 감사하겠습니다.
네트워크란?
네트워크(network)는 보통 상호 간의 소통과 연결 하는 통로를 지칭할때 사용한다. 방송 네트워크도 네트워크도 사람들 간의 모임도 네트워크의 일종이다. 컴퓨터 과학에서의 네트워크도 동일한 용어로 사용된다. 컴퓨터끼리 연결되어 상호간에 데이터를 주고 받는, 즉 통신을 하는 시스템을 컴퓨터 과학에서도 네트워크 혹은 컴퓨터 네트워크라고 지칭한다. 앞으로 네트워크라고 하면 기본적으로 컴퓨터 네트워크를 칭한다.
이렇게 정의를 내리니까 네트워크라는게 뭔가 위대하고 거창하고 대단해보인다. 물론 그렇긴 하지만 미리 겁먹을 필요는 없다. 네트워크는 이미 일상 곳곳에 녹아있다.
출퇴근 시에 사람들이 무선 이어폰으로 음악을 듣는 행위도 스마트폰과 무선 이어폰이 네트워크를 이루고 있기에 가능한 일이다. 이 네트워크에는 단 2대의 기기가 연결되어 있는 셈이다. 좀 더 큰 네트워크도 있다. 가정에서 사용하는 인터넷 공유기가 좋은 예이다. 요즘 시대에는 혼자 살아도 스마트폰, 노트북, OO도 스위O, 태블릿 등등 여러 대의 기기가 인터넷 공유기에 접속해있다. 이것도 네트워크다. 하지만 공유기만 있고 인터넷 가입을 하지 않았다면 공유기를 통해 까또크도 쓸 수 없고 웹으로 뉴스도 볼 수 없다. 즉 우리가 인터넷이라 부르는 더 큰 네트워크와의 접속이 필요하다.
인터넷
이미 생활에 녹아든 단어지만 정확한 실체를 모르는 단어 중 하나가 인터넷이다. 인터넷은 사이, 중간을 뜻하는 영어 단어 inter와 네트워크의 합성어이다. 크리스토퍼 놀란 감독의 인터스텔라(Interstellar) 역시 inter와 라틴어로 별을 뜻하는 stellar의 합성어로 별과 별 사이라는 뜻이다. 즉 인터넷은 여러 조직이 다루는 각각의 네트워크와 네트워크가 모종의 규약으로 묶여 있여있는 큰 네트워크라고 이해하면 된다. 참고로 그 조직의 네트워크를 AS(Autonomous System)이라고 한다. KT, LG U+, SK 브로드밴드처럼 인터넷 서비스를 제공하는 ISP(Internet Service Provider, 인터넷 서비스 제공자), 구글이나 AWS같은 대규모 클라우드 운영자 등이 대표적인 AS의 예로 들 수 있다.
운영 주체
네트워크 집합체인 인터넷은 사실 명확한 운영 주체가 없다. 그렇지만 각 네트워크 사이의 자원 배분 및 사용 규칙이나, 표준 기술 제정 등이 필요하기 때문에 굳이 따지면 ICANN(The Internet Corporation for Assinged Names and Numbers)과 IETF(The Internet Engineering Task Force)를 들 수 있다. 도메인 이름(예: google.com)과 IP주소(예: 233.15.22.55) 같은 자원은 중복되어서는 안되기 때문에 ICANN에서 관리한다. 자원 관리가 중점인 ICANN과는 달리 IETF는 인터넷의 기술을 담당한다. IETF는 다양한 인터넷 기술 RFC(Request For Comments)라 불리는 일련의 기술문서를 발행하며 각종 인터넷 표준기술을 제정하는 역할을 한다.
미국으로 데이터 보내기(간략 버전)
처형이 싱가폴에 살고 있다. 아내가 가끔씩 처형에게 우체국EMS를 통해 과자나 옷과 같은 물건을 보내준다. 우체국EMS도 국내 택배 배송 추적처럼 진행 상황을 볼 수 있다.
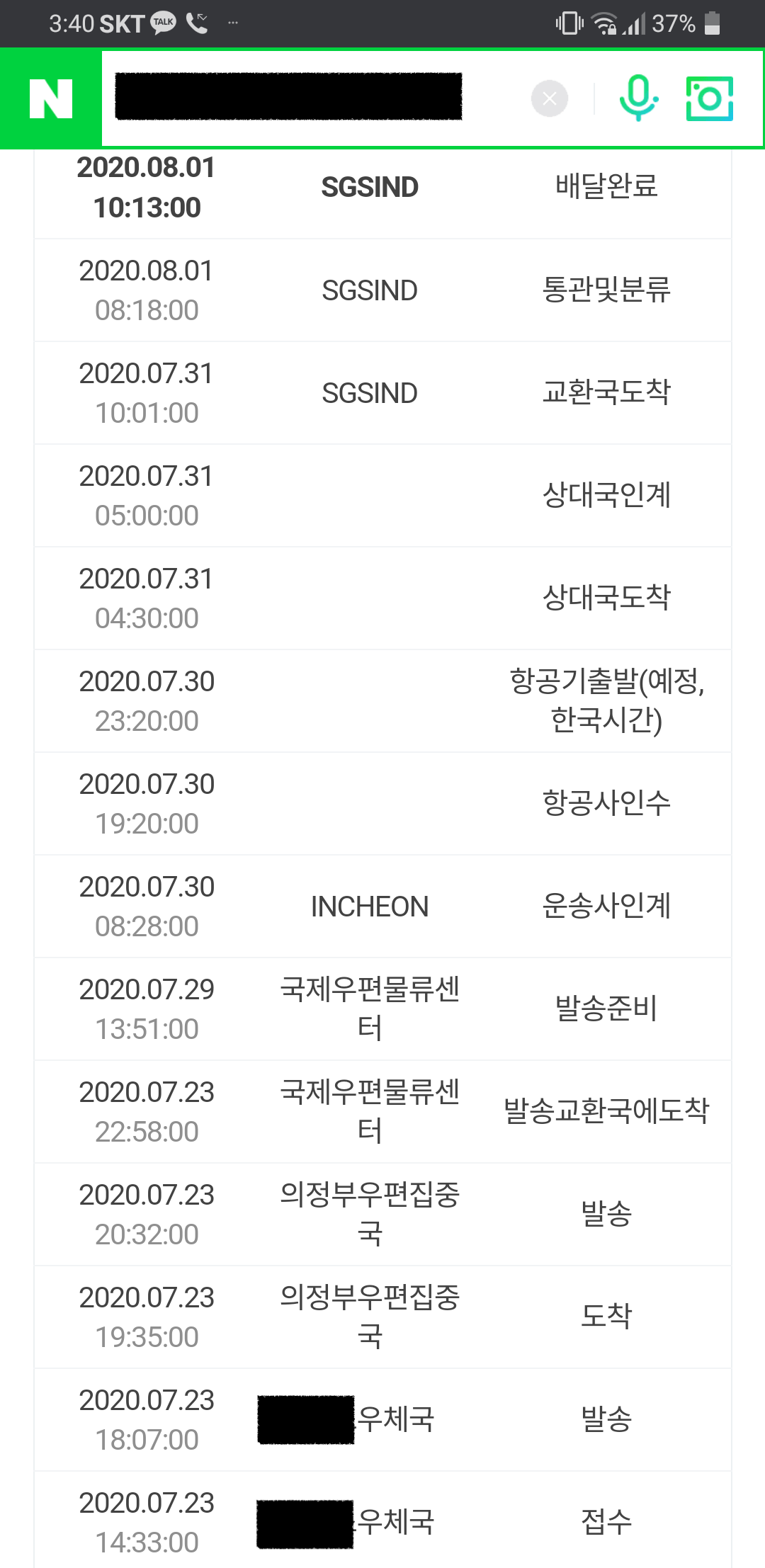
이 추적 경로를 보니 택배건 EMS건 전 세계 네트워크건 동작 방식이 크게 다르지 않다는 사실을 깨달았다. 현재 남양주 모처에서 살고있는데 이곳 지역 우체국에서 보낼 우편물을 맡기면 지역 우체국에서는 우편물을 모아서 트럭으로 우편집중국이라는 곳으로 우편물을 보낸다. 이 곳 우체국EMS는 아마도 의정부 우편집중국에서 담당하나보다. 의정부 우편집중국에 모인 우편물 중 해외로 나갈 우편물만 모아서 트럭으로 국제물류우편센터로 이동하고, 여기서 화물기를 타고 싱가폴로 간다. 싱가폴에서 어떻게 처형에게 갔는지는 모르지만 아마도 남양주 모처->국제물류우편센터의 역순으로 최종 배송지까지 이동했으리라.
미국의 스미스씨와 서로 통신을 주고받는 행위도 이와 비슷하다.
뫄뫄씨가 스마트폰으로 스미스씨에게 메시지를 보낸다고 가정하자. 메시지 어플리케이션이 무선 전파(LTE, 5G)를 통해 메시지를 보낸다. 해당 메시지는 스마트폰의 기지국을 통해서 교환국이라는 곳으로 전달된다. 교환국은 여러 기지국에서 오는 메시지를 모아 인터넷망을 통해 인터넷 데이터 센터로 전달한다.
| 우체국EMS | LTE 네트워크 |
|---|---|
| 동네 우체국 | 기지국 |
| 우편집중국 | 교환국 |
| 국제물류우편센터 | 인터넷 데이터센터 |
미국의 스미스에게 보낸 메시지는 각 통신사 인터넷 데이터센터(국제물류우편센터)를 통해서 한국을 벗어난다. 그 후 우체국EMS에서 비행기로 우편물을 운반하듯이 큰 네트워크 사이를 연결하는 초고속 광케이블을 타고 미국으로 향한다. 이 초고속 광 케이블은 주로 해저에 설치되어 있으며 이런 케이블을 설치하고 관리하는 네트워크 서비스 제공자를 보통 티어(Tier)1 ISP라고 한다. 즉, 스미스에게 보내는 메시지는 이 티어1 ISP의 회선을 타고 해외로 나가는 셈이다.
태평양을 건넌 메시지는 미국의 한 ISP가 받는다. 보통 티어1 ISP에 비용(망사용료라고 한다)을 지불하고 네트워크를 이용하는 ISP를 티어2 ISP라고 한다. 참고로 한국의 SK브로드밴드와 KT가 이 티어2 ISP에 해당한다. 그리고 스미스씨는 이 ISP를 통해서 혹은 또 다른 ISP를 통해서 메시지를 받을 수 있다.
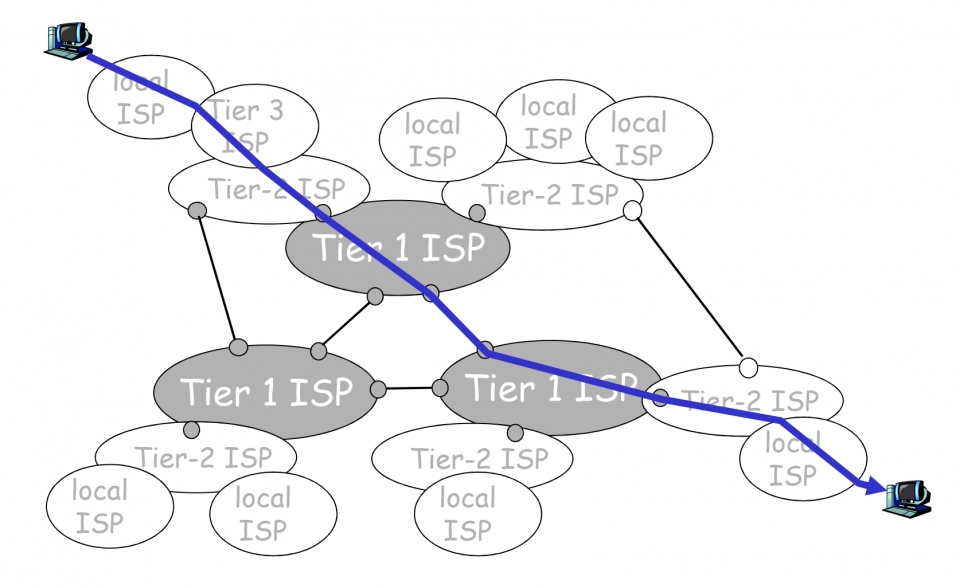
그림 출처: http://www.jaturi.kr/news/articleView.html?idxno=5405
즉 다시 정리해보면 한국의 뫄뫄씨는 모바일로 미국 스미스에게 메시지를 보내는 상황이다. 뫄뫄씨는 티어3 ISP인 SK, KT, LG U+ 를 통해 메시지를 보낸다. 이들을 티어3 ISP라 하며 트래픽 전량을 티어2 ISP로 부터 사들인다. (근데 한국의 이동통신사들은 자체 유선통신망도 가지고 있어서 같은 티어1,2,3이 같은 회사이지 싶다. 이쪽은 제가 잘 몰라서 아시는 분 설명 부탁드립니다.)
티어2 ISP는 티어1 ISP에게 이용료를 지불하고 이들의 망에 접속한다. 티어2 ISP가 티어1 ISP에 접속되어 있기 때문에 미국에 있는 스미스씨에게 메시지를 보낼 수 있다. 한편 뫄뫄씨가 속초에 사는 친구 모모씨에게 메시지를 보낸다하면 티어1 ISP까지 가지 않고 티어2 ISP끼리 이를 처리할 수도 있다. 티어2 ISP끼리는 서로 연결되어 있기도 하기 때문이다.
매우 간략해보이지면 그 안에서는 굉장한 일이 일어나고 있다. 데이터가 이름표와 목적지를 명찰을 달고 움직이고 버스 환승하듯이 네트워크와 네트워크 사이를 갈아타기도 하고 길이 막히면 돌아가기도 하고 길을 잃고 헤매기도 하고 데이터를 전송하기 위해 서로와 서로 사이에 인사를 나누기도 한다.
프로토콜
사람과 사람이 소통하기 위해서 언어가 존재한다. 한국인은 한국인과 한국어를 사용해서 매우 쉽게 소통할 수 있다. 하지만 한국인과 러시아인은 서로 소통을 못한다. 상호 소통의 규약인 언어가 다르기 때문이다. 네트워크 세상에서는 이를 프로토콜(Protocol)이라 부른다. 즉, 네트워크를 구성하는 기기 사이에 미리 약속된 통신 방법과 양식이 프로토콜이다. 허나 하나의 프로토콜만으로는 통신할 수 없기 때문에 콘소시움처럼 여러 프로토콜을 조합해서 사용한다. 이렇게 복수의 프로토콜 집합을 프로토콜 스택(Protocol Stack), 혹은 프로토콜 스위트(Protocol Suite)이라 하는데 한국인과 러시아인이 서로 대화를 나누지 못하듯, 서로 다른 프로토콜 스택끼리는 통신을 할 수 없다.
세상에 여러 네트워크 스택이 있었다. 과거형을 쓴 이유는 현재는 대부분 TCP/IP라는 네트워크 스택을 이용하기 때문이다. Microsoft NetBEUI, Apple Appletalk 등이 있었지만 모두 역사의 뒤안길로 사라진 프로토콜 스택이다. 따라서 네트워크 장에서는 TCP/IP만 설명하도록 하겠다.
TCP/IP 맛보기
사실 TCP/IP는 Internet protocol suite이라는 이름이 있다. 하지만 TCP 프로토콜과 IP 프로토콜을 기반으로 하는 프로토콜 스택이기 때문에 보통 TCP/IP라고 한다. 아까 복수의 프로토콜을 조합한 것이 프로토콜 스택이라 했다. TCP/IP도 복수의 프로토콜을 조합한 프로토콜 스택으로 여러 계층으로 구성되어 있다.
TCP/IP 4계층
TCP/IP를 설명할때, 그리고 시험볼 때 빠지지않는 개념이 있는데 TCP/IP 4계층이라 불리는 녀석이다. 달달 외울 필요는 없고 굳이 머리속에 넣지 않아도 된다. 다만 이러면 디자인 패턴과 같이 다른 엔지니어와 의사 소통에 문제가 있을 수 있으니 알아두는게 좋다.
TCP/IP의 계층 구조는 아래부터 네트워크 인터페이스 계층, 인터넷 계층, 전송 계층(혹은 트랜스포트 계층), 어플리케이션 계층으로 이루어져 있다. 이 4계층의 역할과 각 계층에 속하는 프로토콜을 간략하게 알아보자.
네트워크 인터페이스 계층
네트워크 인터페이스 계층은 물리적으로 데이터를 잘 전송하는 역할을 맡고 있다. 컴퓨터에서 전송하고자 하는 010101010101 데이터는 (한국에서는 흔히 랜카드라고 부르는) 네트워크 어댑터 혹은 이더넷 카드라고 하는 장치를 통해 전기신호 등의 물리신호로 변환하여 발송한다. 여기서 사용하는 프로토콜은 우리가 아는 무선랜(Wi-Fi)나 유선랜(이더넷) 등이 이에 속한다.
한 가지 주의해야 할 점은 단순히 내 컴퓨터에서 나가는 랜선 만이 네트워크 인터페이스 계층의 전부가 아니다. 여러분의 집에 있는 인터넷 모뎀, 나중에 라우팅에서 배우겠지만 네트워크를 구성하는 스위치라는 기기가 모두 네트워크 인터페이스 계층에 속한다.
인터넷 계층
앞서 미국 사는 스미스씨에게 데이터를 보내는 과정을 ISP 티어 1, 2, 3 예를 들어 설명했다. 마치 내가 보낸 데이터는 지하철이나 버스를 갈아타듯이 티어 3 네트워크에서 티어2 네트워크로, 티어 2 네트워크에서 티어 1 네트워크로 갈아타서 최종적으로 미국의 스미스씨에게 도착한다. 인터넷 계층은 이 네트워크 사이에서 데이터를 잘 전송하는 역할을 맡고 있다.
인터넷 계층의 핵심장비는 라우터란 녀석이다. 라우터는 네트워크와 네트워크를 이어주고 데이터의 최종 목적지에 따라 데이터를 다음 라우터로 전송해주는 역할을 한다. 인터넷 계층에 속하는 프로토콜은 IP, ICMP, ARP/RARP 가 있다.
전송 계층
한국사는 뫄뫄씨와 미국사는 스미스씨와의 데이터 전송, 즉 최초 출발지와 최종 목적지 기기 사이의 데이터 전송을 영어로 양단간 통신 혹은 엔드투엔드 통신이라 한다. 전송 계층은 인터넷 계층에서 받은 데이터를 그 상위 계층으로 전달해주는 역할과 어플리케이션 계층에서 넘어온 데이터를 신뢰성 있게 전송을 책임지는 역할을 맡고 있다.
그 상위 계층은 미리 말해두자면 어플리케이션 계층인데, 여러분이 흔히 생각하는 그 어플리케이션이다. 보통 하나의 OS에서는 여러 개의 어플리케이션을 동시에 동작시키기 때문에 전송 계층에서 이 어플리케이션을 구분할 필요가 있다. 이를 포트(Port)라는 논리적인 주소로 구분한다. 마치 데이터를 목적지 아파트까지 배달한건 인터넷 계층, 목적지 아파트에서 원하는 호수로 배달하는건 이 전송계층, 호수는 포트라 생각하면 된다.
대표적인 프로토콜은 TCP (Transmission Control Protocol)과 UDP (User Datagram Protocol)가 있다.
어플리케이션 계층
휴먼과 직접적으로 상대하는 계층이다. 브라우져, 아웃룩, 스카이프, 줌, 카카오톡 등 일상 생활에서 사용하는 프로그램이 어플리케이션 계층이다. 대표적인 프로토콜은 HTTP, POP3, SMTP 등이 있다.
정리하자면 아래와 같다.
| 계층 이름 | 설명 | 주요 프로토콜 |
|---|---|---|
| 어플리케이션 | 응용 프로그램에서 데이터를 처리하는 계층 | HTTP, HTTPS, POP3, SMTP, FTP 등 |
| 전송 | 어플리케이션에서 넘어온 데이터에 대한 검증, 재전송 등 각종 제어를 담당하는 계층 | TCP, UDP |
| 인터넷 | 데이터를 목적지까지 효율적으로 전달하는 방법을 담당하는 계층 | IP, ICMP 등 |
| 네트워크 인터페이스 | 실질적으로 데이터를 전송하는 계층 | Ethernet, Wi-Fi 등 |
HTTP, POP3처럼 어디선가 들어본 단어도 있고 SMTP, ICMP처럼 처음 처음 들어보는 프로토콜이 있으리라. 지금은 설명을 하지 않고 나중에 다룰 기회가 있으니 이런게 있다고만 알고 넘어가도록 하자.
TCP/IP을 활용한 데이터 흐름
캡슐화와 역캡슐화
앞서 TCP/IP는 4개의 프로토콜이 계층적으로 조합된 프로토콜 스택이라고 말한 바 있다. 데이터 전송의 주체가 되는건 여러분들이 사용하는 카톡같은 어플리케이션이다. 데이터 전송은 대체로 요청과 응답 이렇게 양방향으로 이루어진다. 어플리케이션에서 데이터를 전송할 때는 상위 계층에서 하위 계층으로 데이터가 이동하고 어플리케이션이 데이터를 수신할 때는 데이터가 하위 계층에서 상위 계층으로 이동한다. 상위 계층에서 하위 계층으로 데이터가 이동할 때는 그 계층마다 필요한 정보가 필요하다.
예를 들어 책을 택배로 보내고 싶다면 책을 포장해서 그 위에 자신의 주소와 받을 상대방의 주소를 써넣어야 한다. 그럼 택배사가 이 주소를 보고 배송에 필요한 정보(예: 옥천 버뮤다로 가라)를 택배 상자 위에 붙인다. 이런 추가 정보를 프로토콜에서는 이를 제어 정보 혹은 헤더라고 한다. 헤더는 하위 계층으로 내려갈때마다 추가 되는데, 이렇게 헤더를 추가하는 행위를 캡슐화라고 한다. 반대로 상위 계층으로 올라갈 때마다 추가한 헤더를 읽고 알맞은 행동을 취한 후, 헤더를 제거하는데 이를 역캡슐화라고 한다.
웹 브라우저로 이미지 파일 불러오기
여러분들은 모바일 혹은 노트북(PC)의 웹 브라우져로 지금 이 글을 읽고 있다. 이 글에는 아래와 같이 귀여운 강아지 사진이 있다.

이 멋진 이미지를 읽기 위해서는 여러 절차가 필요하다. 크롬이나 파이어폭스 등의 웹 브라우저는 이 페이지를 구성하고 있는 html 파일을 읽는다. "img" 태그를 만나면 해당 주소에 있는 서버에 이미지를 요청한다. 예를 들어 https://csbooks.wisedog.net/aaa.jpg라고 하자.
첫 번째. 먼저 웹 브라우저는 csbooks.wisedog.net이라는 곳에 이미지를 요청하는 메시지를 만든다.
두 번째. 웹 브라우저는 이 메시지 앞에 HTTP 헤더라고 불리는 정보를 붙인다. 이 이미지의 주소, 사용 언어 등등의 정보가 이에 해당된다. 앞서 설명한 캡슐화에 해당한다. 앞으로 계층을 하나씩 지날 때마다 이런 캡슐화과정을 거치게 된다.
세 번째. 웹 브라우저는 OS의 시스템 콜을 사용해 TCP 연결을 열고 데이터를 보낸다. 시스템 콜은 2장 4절 컴파일러 시간에 배웠듯이 OS가 제어하는 자원-여기서는 네트워크 자원-을 요청할 때 사용한다. 여기까지가 웹 브라우저의 영역이며 어플리케이션 계층이다. 참고로 어플리케이션 계층의 데이터를 메시지라고 부른다. HTTP프로토콜을 사용했다면 HTTP 메시지라고 부른다.
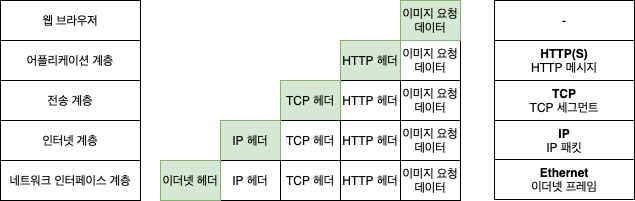
네 번째. 지금부터는 OS 영역이며 전송 계층이다. OS는 TCP 연결을 통해 HTTP 메시지에 TCP 헤더라고 불리는 정보를 붙인다. 어플리케이션의 포트 정보와 각종 제어정보가 들어간다. TCP/IP 제어 관련은 별도의 절에서 설명하도록 한다. 참고로 전송 계층의 데이터를 세그먼트라고 부른다.
다섯 번째. OS에서 TCP 세그먼트에 목적지 IP 주소 등의 정보 등의 정보를 조합한 IP 헤더를 붙여서 이더넷 카드로 보낸다. 여기까지가 인터넷 계층이다. 참고로 인터넷 계층의 데이터를 패킷이라고 부른다. 잠깐, IP가 뭐냐구요? 한 마디로 말하자면 인터넷 상에서 각 기기별로 가지는 고유한 주소다. 아파트도 중복된 동호수가 없듯이 IP는 중복된 주소가 없다. DNS(Domain Name Service)를 통해서 csbooks.wisedog.net의 주소를 알아낼 수 있다.<추후>
여섯 번째, 이더넷 카드에서는 IP 패킷에 이더넷 헤더에 보너스로 오류 검출을 위한 트레일러라는 데이터를 패킷 뒤에 추가로 붙여서 이더넷 프레임을 만든다. 참고로 네트워크 인터페이스 계층의 데이터를 프레임이라고 부른다. 이더넷 헤더에는 MAC주소라는 정보를 넣는다.(MAC주소는 랜카드의 고유ID라 생각하면 된다) 그리고 이 데이터를 전기 신호로 전환해서 랜선이나 무선랜을 이용하여 외부로 보낸다.
네트워크에서 네트워크로
여러분의 컴퓨터에서 나간 이더넷 프레임이 목적지에 도달하기 위해서는 여러 기기를 거쳐야 한다. 집안에서 무선랜을 통해 인터넷을 한다고 가정하면 아마 먼저 여러분의 데이터를 맞이하는 장비는 스위치라는 장비이다. 스위치는 자신과 연결된 라우터에 이더넷 프레임을 전달한다. 라우터는 스위치로부터 온 전기 신호를 0101010로 된 데이터로 변환해서 이더넷 프레임을 읽어들인다. 그리고 이더넷 프레임의 헤더를 제거하고 그 상위 데이터인 IP 패킷을 읽는다. 이 과정은 앞서 설명한 역캡슐화에 해당한다.
라우팅에 관한 내용은 별도의 장에서 더 상세하게 설명하도록 하겠지만, 여기서 간략하게 맛보기 정도만 언급하자면 라우터는 역캡슐화를 통해 읽어들인 IP 패킷에서 목적지 IP 주소를 추출해서 이 패킷이 어디로 전달되어야 할지를 결정한다. 라우터에는 라우팅 테이블(Routing Table)이라는 정보가 있어서 가능한 일이다. 라우팅 테이블에는 목적지 IP 주소와 이를 위해 다음에 전달할 주소 정보를 가지고 있다.
| 목적지 주소 | 다음에 전달할 주소 |
|---|---|
| 223.152.0.0 | 115.33.14.33 |
| 53.65.0.0 | 55.44.33.22 |
| ... | ... |
아까 예를 든 csbook.wisedog.net의 주소가 223.152.43.22 라고 한다면 라우터는 115.33.14.33 주소로 해당 패킷을 보내야 한다는 사실을 알고 다시 데이터를 캡슐화하여 이더넷 프레임을 만들어서 115.33.14.33로 전달한다.
라우터에서는 TCP 세그먼트와 HTTP데이터는 읽어보지 않는다. 여기서 생략된 개념은 네트워크ID, 서브넷 등이 있는데 이는 추후 알아보도록 하자.
응답 받기
천신만고끝에 이미지 달라는 요청을 받은 csbook.wisedog.net 컴퓨터는 여러분들이 요청을 보낼때 행했던 과정의 역순으로 요청을 처리한다.
첫 번째. 네트워크 어댑터에서 전기 신호를 다시 01010101과 같은 이진 데이터로 변환하고 이더넷 프레임에서 헤더를 떼서 상위 계층으로 전달한다. 여기가 네트워크 인터페이스 계층이다.
두 번째. 네트워크 인터페이스 상위 계층은 무엇? 인터넷 계층이다. 인터넷 계층의 프로토콜은 무엇? IP 이다. IP 패킷에서 IP 헤더를 제거하고 전송 계층으로 전달한다.
세 번째. 인터넷 계층의 상위 계층은 전송 계층이다. 보통 OS가 담당하는 영역인데, OS는 TCP 헤더를 떼고 알맞은 어플리케이션으로 데이터를 전달한다. 이때 확인하는게 포트 번호이다. 같은 프로그램을 동시에 실행 중이더라도 포트가 다르기 때문에 단 하나의 어플리케이션에게만 데이터가 전달된다.
네 번째. 여러분이 이미지를 간절하게 원하고 있다는 사실을 확인한 어플리케이션(즉 웹서버)은 이미지 정보를 응답한다.
응답은 여러분들이 요청을 보낼때와 반대의 절차로 진행된다.
지금까지 개략적인 데이터의 흐름을 알아봤다. 다음 절부터는 좀 더 상세한 절차를 알아보도록 하자.
TCP
사람 사이의 네트워킹에는 많은 일들이 생긴다. 조별 과제를 하는데 팀장이 잠수타거나, 출근 도중에 다리를 삐끗해서 출근을 못할 수도 있다. 컴퓨터 네트워크도 마찬가지인데 모바일로 온라인 동영상을 보면서 LTE 신호가 안 통하는 엘리베이터를 탈 수도 있고, 고양이가 선을 갉아먹어서 신호가 정상적으로 전달이 안되는 경우도 많다. 그런 경우마다 어플리케이션에서 처리해야 할까? 그렇지 않다. TCP는 어플리케이션 간의 신뢰성 있는 데이터 전송을 하기 위한 프로토콜이다. 여기서 말하는 '신뢰성'을 위해서는 TCP 이전에 알아야 할 지식이 있다.
회선 교환 vs 패킷 교환
네트워크 전송 방식에는 2가지가 있다. 회선 교환(Circuit Switching) 방식과 패킷교환(Packet Switching) 방식이다. 회선 교환방식은 쉽게 생각하면 유선 전화라고 생각하면 된다. 통화가 연결되면 상대방과 내 사이에 전용 통신선이 생기고 통화가 끝날 때까지 이 통신선이 없어지거나 다른 통화와 공유가 되지 않는다. 반면 패킷교환 방식은 우편이라고 생각하면 된다. 하고 싶은 말을 여러 편지에 나눠서 보낸다. 물론 중간에 없어질 수도 있으며 두 번째 보낸 편지가 첫 번째 보낸 편지보다 먼저 도착할 수도 있다.
인터넷 네트워크는 회선 교환 방식을 사용하지 않고 패킷 교환 방식을 사용하여 데이터를 보낸다. 회선 교환 방식을 사용한다면 네트워크에 참여하는 단말이 많으면 많아질수록 회선 수를 급격하게 늘려야 한다. 반면 패킷 교환 방식은 여러 사람의 데이터를 패킷 형태로 한 회선에서 사용할 수 있다.
| 회선 교환 | 패킷 교환 | |
|---|---|---|
| 회선 | 전용 회선 | 공유 회선 |
| 장점 | 속도, 신뢰성 | 효율 |
| 단점 | 효율성 | 속도, 신뢰성 |
아까 귀여운 강아지 사진을 보았을텐데, 이 사진의 크기가 100 KB라 가정해보자. 이론상 한 번에 보낼 수 있는 TCP세그먼트의 크기는 65KB이라서 100KB라면 2개로 쪼개서 보낼 수 있을 것이다. 하지만 보통 OS에서 설정한 MTU(Maximum Transmission Unit)값을 따른다. 이 값은 보통 1500바이트인데, 네트워크 인터페이스에서 분할(세그먼트) 없이 보낼 수 있는 최대 크기이다. 보통 IP헤더 20바이트, TCP 헤더 20바이트 뺀 1460바이트씩 보낼 수 있다. 따라서 강아지 사진을 한 장 받기 위해서는 데이터를 전송하는 측에서는 수 천 ~ 수 만 개의 TCP세그먼트로 분할하고 받는 호스트에서는 분할된 TCP세그먼트를 조합한다.
TCP 데이터 전송 프로세스
TCP로 어플리케이션간 데이터 전송은 크게 아래 절차를 통해 진행된다.
TCP 연결 맺기 -> 어플리케이션 사이에 데이터 송수신 -> TCP 연결 끊기
0. 메시지 타입
| 메시지 | 설명 |
|---|---|
| SYN | Synchronize Sequence Number의 약자. 연결 초기화 및 연결 성립에 사용된다. 두 기기 사이에 시퀀스 번호(Sequence Number)라는 데이터를 동기화할때도 사용한다. |
| ACK | Acknowledgement의 약자. SYN 메시지를 받은 쪽에서 잘 받았다고 확인할때 보내준다. |
| FIN | 연결을 종료할때 사용한다. |
1. TCP 연결 맺기
통신 상대방과 자신 양쪽 모두 데이터 전송할 준비가 되었다는 것을 확인하고 3웨이 핸드셰이크라고 불리는 과정을 통해 논리적인 연결을 맺는 과정이다. 회선 교환처럼 물리적 연결을 맺는게 아니다. 3웨이 핸드셰이크라는 용어가 영어라서 어렵게 생각할 수도 있겠지만 전화 거는 행위와 같다고 생각하면 쉽다. (읽을 때는 삼 웨이 핸드셰이크가 아니라 쓰리 웨이 핸드셰이크라고 읽어야 한다 ㅠㅠ. 혹시나 해서요...)
발신자 A, 수신자(콜센터) B의 경우 통화 프로세스가 보통 아래와 같을 거다. 생각하는 것과 달라도 그렇다고 알고 가자.
A: (전화를 건다)
B: 안녕하세요, ㅇㅇㅇ 입니다.
A: 네, 전 XXX 인데요, 이거이거에 대해서 설명해주세요
.....
웹브라우져 A와 웹서버 B와의 통신도 이와 유사하다.
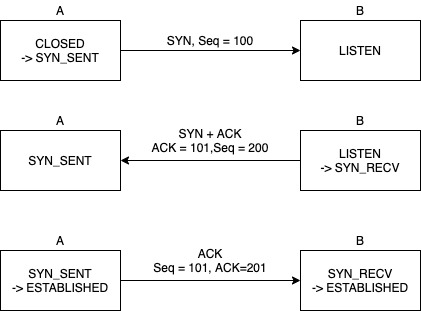
- A -> B
전화 거는 상황이다. A가 B에게 SYN 메시지 전송한다. A는 첫 연결 시 랜덤한 숫자(시퀀스 번호)를 같이 보낸다. 여기서는 100이라고 하겠다. A의 상태는SYN_SENT가 된다.
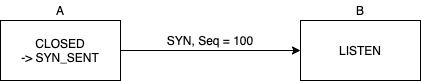
- B -> A
B가 "안녕하세요 ㅇㅇㅇ입니다" 하는 상황이다. 콜센터처럼 웹서버B는 언제나 80포트가 열려있는 상태이기 때문에 B는 메시지를 받을 수 있다. 보통 LISTEN 상태라고 한다. 메시지를 받은 B는 A도 포트를 열라는 메시지(SYN + ACK)를 전송하는데 ACK를 100 + 1인 101을 보내고 자신의 시퀀스 번호를 태워 보낸다. 여기서는 200이라고 하자. 그 후 B는SYN_RECV상태가 된다.

- A -> B
A가 "네, 전 XXX인데요"까지 말하는 상태이다. SYN+ACK 메시지를 받은 A는 웹 서버에게 난 준비되었고 잘 받았다는 메시지를 보낸다. A는 시퀀스 번호를 101, ACK 번호를 B가 보낸 시퀀스 번호 200에 1을 더해서 보낸다. A의 상태는ESTABLISHED가 되며 이 메시지를 받은 B도ESTABLISHED상태로 바뀐다. 이렇게 연결이 성립(ESTABLISHED)된 후 데이터를 주고 받게 된다.

전체적으로 보면 아래와 같다.
2. 어플리케이션 사이에 데이터 송수신
전화로 치면 용건을 이야기하는 단계이고 컴퓨터는 데이터를 주고 받는 단계이다. 아까 콜센터를 예로 들었는데 OOO에 대해서 설명해달라고 하면 콜센터는 계속 설명을 할 것이다. 근데 A가 아무 응답 없이 듣고만 있다면 "여보세요? 제 말 듣고 계세요?" 몇 번 확인하다가 끊어버릴 것이다. A는 중간 중간에 잘 듣고 있다는 "예", "네네" 등의 추임새를 넣어줘야한다. TCP 통신도 마찬가지라서 A에서 데이터를 주면 B는 잘 받았다는 추임새 - ACK를 던져줘야 한다.
3. TCP 연결 끊기
연결을 맺는 과정처럼 연결을 해제하는 과정도 절차가 있다. 연결을 해제하기 위해 4번의 통신이 필요하기 때문에 4웨이 핸드셰이크라고 한다. 이 부분은 3웨이 핸드셰이크와 큰 차이가 없기 때문에 설명을 생략한다. 분량이 남으면 추가해서 넣도록 한다.
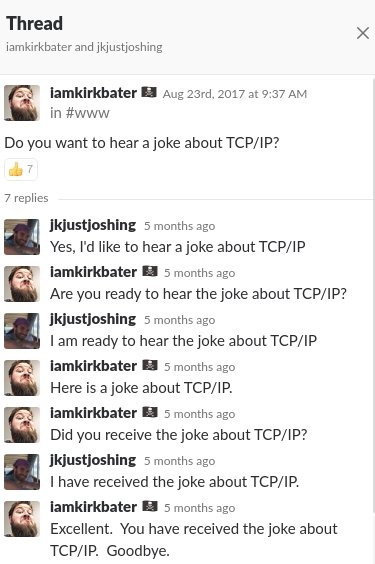
축하한다. 여러분은 아래와 같은 TCP Joke 를 이해할 수 있게 되었다.
오류 제어, 흐름 제어, 혼잡 제어
TCP로 통신을 하면 몇 가지 문제가 발생한다.
첫 번째, 먼저 전송한 패킷이 늦게 도착하거나 일부 패킷이 도착하지 않을 수도 있다. 앞서 서버에서 귀여운 강아지 사진을 전송하기 위해 사진 데이터를 분할해서 보낸다고 했다. 하지만 분할된 강아지 사진이 순서대로 클라이언트에게 도착한다는 보장이 없다. 또한 100번째 강아지 사진이 중간에 어디론가 증발해서 클라이언트에게 도착하지 않을 수도 있다.
TCP가 이를 해결하는 방법이 바로 TCP를 신뢰성있는 프로토콜이라 부르는 이유가 된다. 이를 오류 제어(Error Control) 기법이라고 하며 데이터를 순서대로 정렬하며 못 받은 패킷이 있으면 재전송을 요청하는 등 최대한 데이터 손실이 없도록 노력하기 때문에 인터넷 계층 위의 어플리케이션 개발자가 데이터 송수신에 연연하지 않고 프로그래밍에 전념할 수 있다.
두 번째, 데이터를 보내는 호스트가 데이터를 받는 호스트보다 데이터 처리 속도가 빠르면 문제가 된다. 그 반대의 경우는 상관이 없다. 데이터를 받는 측에서는 버퍼라고 하는 일종의 공간을 사용하여 받은 데이터를 임시 보관한다. 그런데 이를 처리하기도 전에 데이터가 물밀듯이 들어온다면 버퍼에 담기지 못하는 데이터는 손실된다.
이를 위해 TCP에서는 흐름 제어(Flow Control)라는 기법을 사용한다. 자세한 설명은 영문판 위키피디아를 참조한다.
세 번째, 네트워크가 혼잡할 경우에는 데이터가 손실되거나 처리속도가 눈에 띄게 떨어질 수 있다.
이를 위해 TCP에서는 혼잡 제어(Congestion Control)라는 기법을 사용한다. 자세한 설명은 위키피디아를 참조한다.
IP
IP(Internet Protocol)은 TCP/IP 중 IP를 맡고 있는 프로토콜이다. 앞서 설명한 TCP 프로토콜의 역할을 한 마디로 정의하자면 인터넷 계층에서 오는 데이터를 알맞은 어플리케이션으로 보내는 일이라면 인터넷 계층에 해당하는 IP의 역할은 양단간 통신 혹은 엔드투엔드 통신이라 불리는 단말(PC, 모바일 등등)와 단말(PC, 모바일 등등) 사이에 전송을 책임진다.
IP 주소 (IP Address)
택배를 보낼때 내 주소와 상대방의 주소가 필요하듯 IP 역시 자신의 IP주소와 보내는 IP 주소 정보가 반드시 필요하다. IP주소는 총 32비트로 이루어져 있다. 하지만 사람이 11000000101010000000000000000010 이런걸 외우기는 커녕 말하기도 힘드니까, 보통 이를 8비트씩 끊어서 표기한다.
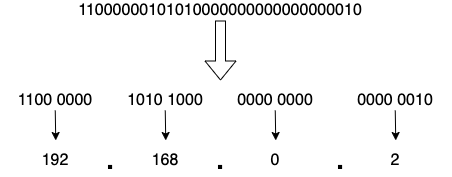
이를 도트형 10진 표기(dot-decimal notice 또는 dotted-quad sequence) 라고 한다. 각각 8비트씩 모여서 하나의 숫자를 이뤘기 때문에 이 숫자를 옥텟(Octet)이라고 부르고 8비트로 이뤄진 숫자이기 때문에 2^0 ~ 2^8, 즉 0~255 사이의 숫자를 표현할 수 있다. 따라서 277.111.222.33 같은 IP 주소는 절대 존재할 수 없다. 이 사실을 알았으니 검찰 사칭 보이스피싱이 여러분의 IP를 알고 있다면서 저런 IP 불러주면 여러분은 이제 현명하게 대처할 수 있다.
이 IP주소는 인터넷 세계에서 절대 겹치지 않도록 앞서 말한 ICANN이라는 단체에서 관리하고 있다. 자기 컴퓨터의 IP를 확인해보는 방법은 리눅스/Mac OS라면 콘솔에서 ifconfig, 윈도우즈라면 cmd 에서 ipconfig를 실행시켜보자.
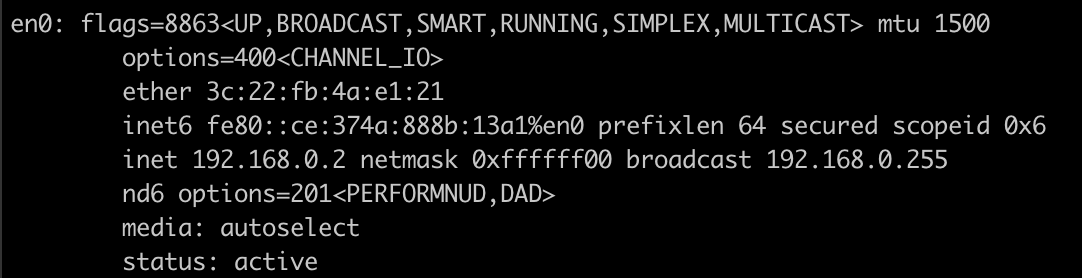
위는 글쓴이의 Mac의 ifconfig 설정이다. 보통 맥의 경우에는 en0를 보면 된다. 나의 IP주소는 192.168.0.2 이다. 어 근데 회사 컴퓨터도 192.168.0.2이고 친구 컴퓨터도 192.168.0.2인데 IP는 유일무이하다고 하지 않았습니까!?
좋은 질문이다. IP주소는 이용 범위에 따라서 공인 IP 주소와 사설 IP 주소로 구분할 수 있다. IP주소가 다음 범위에 있다면 사설 IP주소 이다.
- 10.0.0.0 ~ 10.255.255.255
- 172.16.0.0 ~ 172.31.255.255
- 192.168.0.0 ~ 192.168.255.255
사설 IP주소는 보통 인터넷 공유기나 회사 내 네트워크 같은 사설 네트워크에서 사용하는데, 이 사설 IP주소를 사용해서는 인터넷 통신을 할 수 없다. 목적지 주소가 저 IP 대역대에 속한 IP 패킷이 들어오면 보통 ISP들이 그냥 그 패킷을 버려버린다. 따라서 공인 IP가 있어야 인터넷 통신이 가능한데, NAT(Network Address Translation)을 사용하면 사설 IP 주소를 사용하여 통신을 할 수 있다.
참고로 사설 네트워크 내에서만 IP가 중복되지 않으면 되고, 다른 사설 네트워크와는 IP가 겹쳐도 상관없다. 옆집 IP Time 인터넷 공유기에 접속한 핸드폰도 아마 192.168.0.1 혹은 192.168.0.2 일테니까. 한 아파트 단지를 탈탈 털면 192.168.0.1이 몇 백명은 나올 것이다. 이런 일은 없겠지만 혹시라도 검찰을 사칭하는 보이스 피싱이 범죄에 연루된 IP를 조사하니 여러분이 썼던 192.168.x.x가 나왔다고, 빨리 돈을 입금시키라고 겁주면 한껏 비웃어주도록 하자.
만약 인터넷 공유기를 사용하지 않았다면 사설 IP가 아닌 공인 IP를 확인할 수 있다.
백엔드/DevOps 개발자는 Kubernetes, 줄여서 k8s 라는 컨테이너 오케스트레이션시 사용하는 도구를 만질 일이 있을 수 있다. k8s 안에서 Pod라는 단위가 있는데 Pod도 IP를 할당받아서 서로 통신을 주고받는다. 그런데 할당된 주소는 보통 10.OOO.OOO.OOO로 시작한다. 즉! 이 IP로 직접적으로 인터넷이랑 통신할 수 없다. 외부와의 통신은 Ingress라는 서비스를 통해서 할 수 있다.
IP 주소 체계
서울특별시 마포구 상암동 일대에는 많은 미디어 업체가 자리를 잡고 있다. MBC, YTN, TVN, JTBC 등이 대표적이다. 그래서 TVN 드라마를 보면 차 내부 씬은 열이면 다섯 이상은 월드컵북로를 배경으로 하고 있다. 옛 생각을 떠오르다보니 말이 이상한데에 샜는데, 월드컵북로에 '누리꿈스퀘어'라는 빌딩이 있다. 상암MBC 바로 앞에 있는 빌딩인데, 특이한건 여기 택배 시스템이었다. 이 빌딩을 목적지로 하는 (거의) 모든 택배는 배송 기사가 최종 수령인인 개인에게 직접 전달하지 않고 지하에 있는 택배 보관소에 운송되며 최종 수령인은 택배 보관소로 가서 택배를 찾아간다.
예를 맡게 든지 모르겠지만 IP주소도 이와 비슷하다. IP주소는 단순히 32비트로 이루어진 숫자로 보이지만 내부적으로는 좀 더 효율적으로 네트워크를 찾기 위해 네트워크ID와 호스트ID라는 두 개의 부분으로 구성되어 있다. 네트워크ID는 '서울특별시 마포구 상암동 월드컵북로 396 누리꿈스퀘어'가 되며 '7층 멋진컴파니 OO사업부'는 호스트ID가 된다. 택배기사는 네트워크 ID만 확인하고 누리꿈스퀘어 지하로 택배배송을 해주고 그냥 가버린다. 네트워크 세상에서의 택배기사는 라우터라는 장비인데, 이 장비도 네트워크 ID로 각 네트워크를 식별한다.
주소처럼 IP주소의 전반부가 네트워크ID이며 후반부가 호스트ID이다. 그럼 전반부와 후반부를 나누는 경계선은 어디인가? 앞 12비트 입니다. 라고 말하고 싶지만, 네트워크ID와 호스트ID의 경계선은 고정되어 있지 않고 유동적이다. 이 경계선은 서브넷 마스크라는 값에 의해서 결정된다. 이렇게 유동적인 이유는 IP주소를 효율적으로 사용하기 위해서다.
컴퓨터 공학에서 특정 자리의 숫자 값만 뽑아내고 싶을때 쓰는 기법을 마스킹이라고 한다. 이름은 거창한데 숫자에 다른 숫자를 그냥 AND 한 것 뿐이다. 1장에서 AND 연산에 대해서 배운 적 있다. 입력되는 두 수가 모두 1일 때만 1을 출력하는데, 마스킹은 이를 자릿수 레벨에서 수행한다.
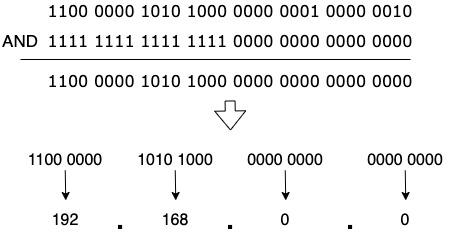
예를 들어 255라는 십진수는 이진수로 1111 1111 인데 이를 192라는 이진수 1100 0000과 AND 연산을 하면

앞 2자리의 1은 피연산자 2개가 모두 1이기 때문에 결과가 1, 그 외에는 하나만 1이기 때문에 결과가 0이 나온다. 즉 그 결과는 192가 나온다. 서브넷 마스크의 사용 방법도 이와 동일하다. 서브넷 마스크 역시 IP주소와 동일하게 32비트로 되어 있는데, 네트워크 ID와 호스트ID의 경계선이 16자리라면 서브넷 마스크는 1111 1111 1111 1111 0000 0000 0000 0000, 네트워크ID와 호스트ID의 경계선이 8자리라면 서브넷마스크는 1111 1111 0000 0000 0000 0000 0000 0000이 된다.
서브넷 마스크도 IP와 같은 이유로 도트형 10진 표기를 사용한다. 1111 1111 1111 1111 0000 0000 0000 0000 의 경우에는 255.255.0.0이 된다. 이 방법 외에도 프리픽스 표기라고 하는 방법도 많이 쓰는데, 서브넷 마스크가 반드시 1이 연속된다는 법칙에 착안하여 /뒤에 연속된 1의 갯수를 적는 경우가 있다. IP 주소/숫자로 표기하는데 만약 192.168.0.2 IP의 서브넷이 255.255.255.0이라면 192.168.0.2/24로 표기한다.
예를 들어 192.168.1.1/16 이라면 네트워크 ID는 192.168.0.0 이 된다.
이렇게 구해진 네트워크 ID는 라우터에서 사용한다. 앞서 라우터와 라우팅에 대해서 짧게 설명한 적이 있다. 라우터는 라우팅 테이블이라는 정보를 이용해서 IP패킷을 전달하는데, 여기서 라우터가 네트워크를 구분할때 쓰는 정보가 네트워크ID와 서브넷이다.
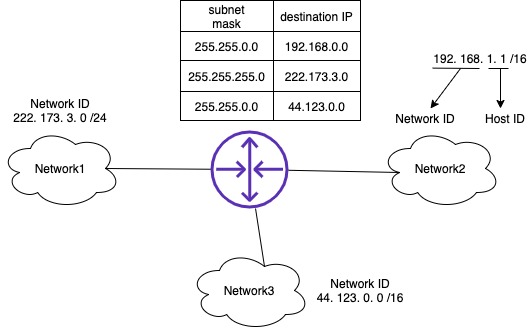
예를 들어 Network2의 한 호스트가 목적지 222.173.3.111에게 패킷을 전송하고 싶다면, 라우터는 라우팅 테이블을 비교해서 222.173.3.111에 마스크 255.255.255.0를 씌운 222.173.3.0의 호스트에게 보낸다는 사실을 알고 IP패킷을 222.173.3.0/24 네트워크로 보낸다.
더 상세한 라우팅 방법은 별도의 장에서 설명하도록 할 예정이다.
유니캐스트와 브로드캐스트
모든 업무용 커뮤니케이션 도구(슬랙, 잔디 등)에서 대화 방법은 크게보면 1:1 대화와 여러 명이 참여하는 대화 방식이 있다. 특히 여러 명이 참여하는 대화방에서 멘션 기능을 잘못쓰면 대화방에 참여한 사람에게 알람이 간다.
IP통신도 이런 방식이 있는데, 1:1 대화처럼 지정한 통신상대와 대화하고 싶을때를 유니캐스트라고 한다. 대부분의 TCP/IP 통신은 이런 유니캐스트 방식이다. 하지만 몇몇 통신은 1:1보다는 전체 공지 방식이 좋을 수 있다. 가장 좋은 예가 ARP(Address Resolution Protocol)라는 프로토콜이다. ARP을 잠시 설명하자면 얘기가 또 삼천포로 빠질 수 있는데....
IP는 목적지 IP주소만 알면 되지만, IP패킷을 실어 나를 이더넷 프로토콜에서는 상대방의 MAC주소라는 걸 알아야한다. 여러분이 사용하는 네트워크 어댑터(흔히 말하는 랜카드)는 고유의 ID가 있는데 이를 MAC주소라고 한다. 문젠 내가 123.123.123.123에 뭔가 데이터를 보내고 싶은데 123.123.123.123의 MAC주소를 어찌 알겠는가? 이럴때 사용하는게 ARP인데 이 IP의 MAC주소 아세요?라고 같은 네트워크에 물어볼 때 사용하는 프로토콜이다. 근데 어느 세월에 한 네트워크에 속한 호스트 하나하나 붙잡고 물어보겠는가. 막말로 한 네트워크에 속한 호스트의 수가 10만 개라면 어느 세월에 끝날지 알 수가 없다. 한 사람 한 사람 붙잡고 물어보는 방식이 유니캐스트라면 이 IP주소의 MAC주소 아시는 분 당장 텨나와라라는 전체 공지 방송은 브로드캐스트 방식이다.
이 브로드캐스트는 네트워크ID 말고 호스트ID 부분을 모두 1로 채운 주소로 데이터를 전송하면 같은 네트워크 안에 있는 호스트들이 모두 수신 가능하다. 앞서 설명했던 IP주소가 192.168.1.1/16인 호스트를 가정하자면 네트워크 ID는 192.168 부분이며 호스트 ID는 1.1 이다. 이 호스트 ID를 모두 1로 바꾸면 255.255가 되기 때문에 192.168.1.1 호스트가 수신 주소를 192.168.255.255로해서 데이터를 보내면 같은 네트워크 내의 모든 호스트(예: 192.168.2.55, 192.167.1.192 등)는 192.168.1.1이 보낸 데이터를 수신하고 필요할 경우 응답을 보낸다.
IP 클래스
여태까지 이상한 예를 들어가며 열심히 서브넷마스크를 설명한 이유는 바로 IP 클래스 때문이다. IP 클래스는 A, B, C, D, E 로 나눌 수 있는데 이를 나누는 기준이 바로 서브넷 마스크이다.
A클래스의 경우 네트워크 ID는 첫 8비트이며 이를 구분해내기 위해 필요한 서브넷 마스크는 1111 1111 0000 0000 0000 0000 0000 0000 - 255.0.0.0이 된다. 프리픽스 표기로는 IP/8이다. A 클래스로 구분할 수 있는 네트워크 수는 2^8인 128개이며 이 네트워크 내에서 IP를 할당해줄 수 있는 기기(호스트)의 수는 2^24 - 2 개인 16,777,214개이다. 왜 2개를 빼냐면 어떤 네트워크에서 호스트ID가 0과 전부 1인 값은 특별한 용도로 사용하기 때문이다. 0으로 채우면 네트워크 자체를 식별하기 위해 이용하는 네트워크 주소가 되며 모두 1을 체우면 전 챕터에 언급한 브로드캐스트 주소 값이라서 일반 호스트에는 할당될 수 없는 IP이기 때문이다.
아래는 각 클래스별 서브넷 마스크, 할당 가능한 네트워크 수와 최대 호스트 수다.
| Class | 네트워크ID Bit수 | 서브넷마스크 | 할당가능한 네트워크 수 | 최대 호스트 수 |
|---|---|---|---|---|
| A | 8 | 255.0.0.0 | 128 | 16,777,214 (2^24 - 2) |
| B | 16 | 255.255.0.0 | 16,384 | 65,534 (2^16 - 2) |
| C | 24 | 255.255.255.0 | 2,097,152 | 254 (2^8 - 2) |
클래스 D는 멀티캐스트라고 해서 앞서 설명한 유니캐스트와 브로드캐스트와는 다른 개념인데, IP대역이 224.0.00 ~ 239.255.255.255까지이며 클래스 E도 있으나 특수용도로 사용하기 때문에 이 클래스 D, E는 설명을 생략하도록 하겠다.
이렇게 클래스를 나누는 이유는 효율적인 IP 자원 배분 때문이다. 예를 들자면 우리 집 네트워크에 A클래스를 할당해주는 경우를 생각해보자. 우리 집 네트워크는 16,777,214개의 호스트에 IP를 할당할 수 있지만 내가 연결할 수 있는 기기는 많아야 5개 정도에 불과해서 16,777,209개의 주소가 낭비된다. 따라서 클래스 A는 아무나 할당하지 않고 국가 단위의 큰 단체나 기업에게만 할당해준다.
CIDR
바로 위에서 IP 클래스를 설명했지만, 사실 요즘에는 네트워크를 클래스 단위로 관리하지 않는다. 클래스 단위의 최소단위는 255개가 되는데 만약 255개가 아니라 30개씩 8개로 나누고 싶다면 울며 겨자먹기로 255 * 8 = 2040개의 IP 대역을 할당받아서 240개의 호스트에게 밖에 IP를 할당할 수가 없게 된다. 그래서 더 효율적인 네트워크 관리를 위해서 CIDR(Classless Inter-Domain Routing)라는 기법을 쓴다. 외쿡인들 발음보니 사이더와 사이다 의 중간 정도로 읽더라.
CIDR는 말 그대로 클래스가 없다(Classless)는 뜻이다. 즉 네트워크 관리의 단위가 클래스 단위가 아니라는 점이 중요하다. 이를 위해서는 서브넷마크스의 역할이 중요한데, 기존에는 클래스 단위로 서브넷마스크가 255.0.0.0(/8), 255.255.0.0(/16), 255.255.255.0(/24) 으로 고정되어 있다면 CIDR은 이 비트가 좀 더 가변적인것이 특징이다.
예를 들어 111.111.111.111/24라면 111.111.111.0 ~ 111.111.111.255 까지 호스트 254개(256 - 2)를 할당할 수 있다. 근데 한 네트워크에 호스트 500개를 할당해야 한다면? 서브넷 마스크를 수정해보자.
111.111.111.111/24는 서브넷마스크가 255.255.255.0(11111111 11111111 11111111 00000000)이다. 여기서 서브넷마스크의 3번째 옥텟에서 숫자 1을 빼보자. 255.255.254.0(11111111 11111111 11111110 00000000)이 된다. 이를 IP 111.111.111.111(01101111 01101111 01101111 01101111)과 AND 연산을 해보면 호스트 ID는 111.111.110.0 이 나온다.
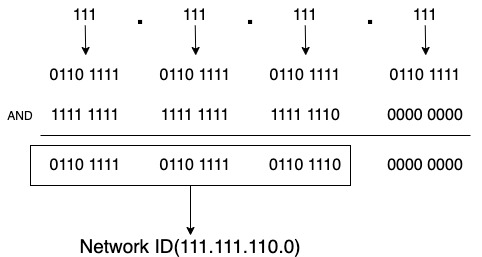
호스트 ID 할당은 총 9자리가 되기 때문에 2^9 -2 해서 총 510개의 호스트를 할당할 수 있다. 표기는 111.111.111.111/23이 되겠다. 같은 방법으로 더 작은 네트워크를 구성할 수도 있다. 단순히 서브넷마크스 값만 변경하면 된다. 아까의 IP 111.111.111.111/24에서 4번째 옥텟의 첫 번째 두 번째 자리를 1로 바꿔보자. 그럼 (11111111 11111111 11111111 11000000)이 되며 서브넷마스크는 255.255.255.192가 된다. 이 네트워크가 할당할 수 있는 IP 대역은 111.111.111.64 ~ 111.111.111.127 이 되며 총 64개의 호스트에 IP를 할당할 수 있다.
이 CIDR은 상당히 많은 곳에서 사용되는데, 예를 들어 AWS의 RDS의 보안그룹을 보면 인바운드 규칙이라는 부분이 있다.

이 설정은 RDS에 접근 가능한 IP를 제약하는 곳인데 만약 내 IP 111.111.111.111만 접속하게 하고 싶다면 111.111.111.111/32 로 적으면 내 IP에서만 RDS에 접근이 가능하다. 서브넷 마스크가 255.255.255.255이기 때문에 IP대역이 딱 111.111.111.111~111.111.111.111 이기 때문이다. 만약 회사 네트워크에서만 접근 가능하게 하고 싶다면? 일단 회사 네트워크 사양을 봐야겠다. 회사 네트워크의 서브넷마스크가 255.255.255.192라면!? 111.111.111.111/26 이라 적으면 IP가 111.111.111.64 ~ 111.111.111.127 사이의 호스트에서 접속이 가능하다.
0과 1가지고 계산하기 힘들다면 온라인 툴을 사용하면 편하다.
DNS
IP는 IP주소로 목적지를 찾아가는 프로토콜이다. 그럼 csbooks.wisedog.net에 데이터를 요청하는 패킷을 싣어 보낼때, IP주소를 어떻게 알 수 있을까? 해답은 바로 DNS(Domain Name System)다. 여러분은 옆 자리에 앉은 동료의 핸드폰 번호를 기억하는가? 아마 높은 확률로 기억 못할 것이다. 기억하지 못한다고 통화를 할 방법이 없지 않다. 스마트폰 주소록 앱에서 "옆자리 망할 놈"이라고 저장된 이름을 찾아서 전화 버튼을 누르면 통화할 수 있기 때문에 일상 생활에 별 지장이 없다. DNS도 마찬가지로 사람이 인식/기억하기 쉬운 정보인 google.com 같은 도메인 이름의 IP주소가 뭐냐는 문의가 들어오면 이에 맞는 IP주소로 바꿔주는 일종의 테이블과 같다고 생각하면 쉽다.
도메인 이름(Domain Name)
여러분은 naver.com의 IP주소를 아는가? daum.net의 IP주소는? 1초내로 답이 튀어나오는 사람은 해당 기업 네트워크 담당자다. 그 외에는 아무도 모른다. 하지만 여러분은 네이버나 다음을 이용하는데 불편함을 느낀 적이 없을 것이다. 축하한다. 여러분들은 자신도 모르게 도메인 이름이라는 기술을 체득한 셈이다.
그렇지만 우리는 이론을 알아야 하는 사람들이기 때문에 좀 더 도메인에 대해서 알아보자. 도메인 이름은 사용자가 쉽게 기억할 수 있도록 문자열과 숫자로 구성되어 있으며, 인터넷 상에서는 유일무이한 존재이다. 이 도메인 이름은 규칙이 있어서 아무렇게나 만들수 없다. csbooks.wisedog.net이라는 도메인 이름을 예로 들어보자.

도메인 이름은 끝에서부터 TLD(Top-Level Domain), SLD(Second-Level Domain, 레벨2 도메인), Third-Level Domain(레벨3 도메인)으로 구성되어 있다. ROOT라는 도메인 아래에 트리를 거꾸로 세워놓은 듯이 구성되어 있다. 위 도메인을 예로 들자면 아래와 같다.
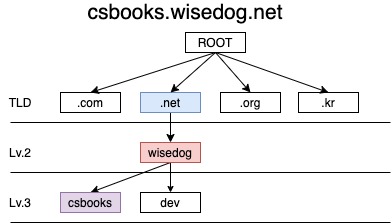
csbooks.wisedog.net의 경우 ROOT 아래 TLD는 .net, 2단계는 wisedog, 3단계는 csbooks가 된다. TLD는 크게 2종류나 3종류로 구분할 수 있다. 크게 2종류로 구분한다면 아래와 같이 구분한다.
- 일반최상위도메인(gTLD: Generic Top Level Domain)
- 국가최상위도메인(ccTLD: Country Code Top Level Domain)
gTLD는 스폰서도메인(sTLD: Sponsored TLD)과 언스폰서도메인(uTLD: Unsponsored TLD)으로 구분된다. 스폰서 도메인은 .edu, .gov와 같은 도메인으로 전체 리스트는 위키피디아를 참조하도록 한다. 그 외에는 모두 언스폰서 도메인이다.
일반 최상위 도메인은 .net, .com과 같은 도메인이고 국가최상위도메인은 국가를 나타내는 ISO 3166-1 Alpha-2 표준에 의거 2자리 영문 알파벳인 부호다. .kr, .jp 등이 이것이다. 다만 영국만 예외적인데, 영국의 ISO 3166-1 표기는 GB지만 ccTLD 부호는 uk를 쓴다. 이 국가도메인은 각 국가 기관들이 관리하고 있다.
여러분들은 .co.kr으로 끝나는 많은 사이트를 방문한 적이 있을텐데, 재미있는 사실은 (없을 수도 있다) kr이 TLD, 2단계는 .co, 3단계가 사이트 이름이다. 예를 들어 이 학교 출신은 아니지만 제주도 가고싶다는 열망을 담은 제주국립대학교를 예로 들면 도메인이 jejunu.ac.kr인데, kr이 ccTLD, ac가 2단계 도메인, jejunu가 3단계 도메인이 된다.
도메인은 도매인 등록 대행 업체에서 이용권리를 살 수 있다. 도메인 자체를 사는게 아니라 일정 기간 임대비용이라 생각해야 한다.
여러분이 google.com을 칠 때
자, 그럼 여러분이 웹 브라우져 검색창에 google.com을 쳤을때, 벌어지는 일을 살펴보면서 DNS가 어떻게 우리의 인터넷 삶에 관여하고 있는지 살펴보자.

사용자가 웹 브라우저에 google.com을 치고 엔터를 누르면 먼저 브라우저의 DNS에 google.com의 IP 주소를 물어본다. 최신 브라우저는 일정 시간 동안 DNS 정보를 캐시하기 때문에 최근에 google.com을 방문했다면 IP주소를 가지고 있다. 만약 브라우저 DNS에서 google.com의 주소를 찾지 못한다면 운영체제(OS)의 DNS에 google.com의 IP 주소를 물어본다.
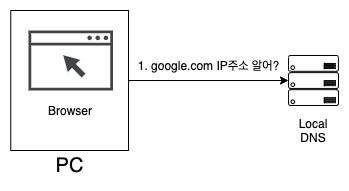
여기서도 찾지 못한다면 근거리 네트워크 혹은 ISP 내에 있는 로컬 DNS라 불리는 DNS가 출동할 차례다. 로컬DNS가 google.com의 IP주소를 찾는 방법에는 2가지가 있다. 하나는 반복적 질의(iterated query)라는 방식이고, 또 다른 하나는 재귀적 질의(recursive query)라는 방식이다.
먼저 반복적 질의를 알아보자.
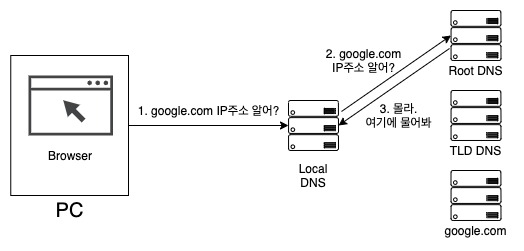
로컬DNS에서 google.com의 IP 정보를 찾지 못하면, 로컬 DNS의 주도하에 google.com의 IP를 찾기위해 드넓은 인터넷에 google.com의 IP주소를 물어보기 시작한다. 로컬 DNS가 맨 먼저 google.com의 IP주소를 물어볼 대상은 루트 네임서버이다. 루트 네임서버는 비영리 단체인 ICANN이 관리하는 시스템이며 2016년 기준으로 전 세계에 632개의 인스턴스에서 수 많은 요청을 처리하고 있다. google.com 같은 유명 도메인의 경우에는 DNS 루트 네임서버가 그 정보를 가지고 있어서 즉각 사용자에게 전달해주겠지만, 일단 그렇지 않다고 가정해보자.
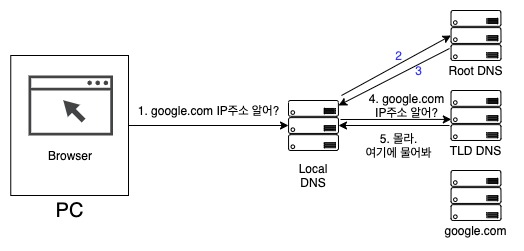
이 경우 루트 네임서버는 최상위 도메인 DNS 서버의 주소를 알려준다. 난 모르니까 여기에서 물어봐 - 이런거다. 로컬DNS가 요청한 주소가 google.com 니까 최상위 도메인은 .com이며 응답으로 .com TLD 네임서버의 주소를 알려준다. 로컬DNS는 이 주소에 대고 다시 google.com의 주소를 물어본다.
만약 TLD 네임서버도 google.com 의 주소를 모른다고 한다면, TLD 네임서버는 google.com의 네임서버 주소를 알려주면서 여기에 물어보라고 한다. google.com의 네임서버 주소라니, 그냥 google.com 주소 아닌가요? 할 수도 있겠지만, 응 아니다. 예를 하나 들자면 여러분이 가XX에서 도메인 주소를 신청했다면 도메인의 네임서버를 반드시 설정하게 되어있다. 보통 ns1.gabxxx.com 이런식으로 되어있는데, 이 ns1.gaxxx.com 라는 주소를 응답해준다.
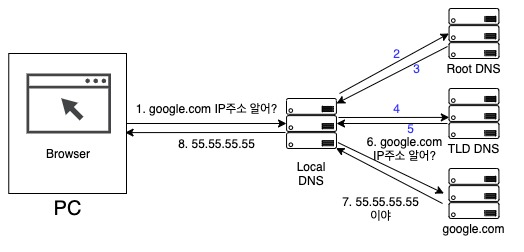
아무튼 TLD 네임서버에서 나는 모르니까 여기에 물어봐라고 준 google.com의 네임서버 주소에 질의를 하면 이제 google.com의 IP주소를 응답해준다. 로컬DNS는 이렇게 어렵게 획득한 IP 주소를 브라우저에 전해주고, 브라우저는 이 IP로 HTTP 요청을 통해 웹페이지를 요청한다.
재귀적 질의는 반복적 질의와 약간 다른데 주인공이 로컬DNS가 아니라 루트 네임서버다. 루트 네임서버가 주소를 모르면 TLD 네임서버에 물어보고, TLD 네임서버도 모르면 google.com 네임서버 주소에 IP를 물어보고 로컬 DNS에 결과를 알려준다..
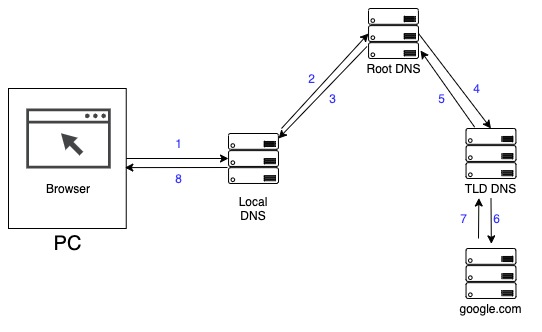
TTL - Time To Live
네트워크를 다루다보면 반드시 알아야할 내용 중 하나가 TTL이다. 아까 예를 든 google.com의 IP주소를 예로 들자면, 만약 어떤 네임서버가 google.com 의 IP주소를 반환하는데 성공했다면, 이 정보를 일정시간 캐시해둔다. TTL은 이 캐시에 저장되는 시간을 의미한다. 네임서버의 캐시에 google.com 의 정보가 있다면 네임서버는 캐시에서 꺼내어 바로 google.com의 IP주소를 반환한다.
TTL이 중요한 이유중 하나는, 웹서비스를 하다보면 가끔씩 IP주소를 바꿔야할 일이 생기기 때문이다. 여러분이 asdf.com 이라는 웹서비스를 운영하고 있는데 이번에 서비스하는 IP주소를 11.11.11.11에서 22.22.22.22로 바꿔야한다고 가정하자. DNS에 대한 이해가 없이 그냥 바꾸면 큰 문제가 생긴다. asdf.com 도메인의 TTL을 1시간으로 잡아놨는데, IP주소를 22.22.22.22로 바꾸고 11.11.11.11 IP를 가진 웹서버를 꺼버렸다고 가정하자. 그 시간 사용자들은 브라우저에 asdf.com를 치고 엔터키를 누르면 DNS에 IP주소를 물어보는데, 네임서버는 이미 기존에 캐싱한 11.11.11.11 을 반환한다. 그럼 웹브라우저는 11.11.11.11 에 데이터를 요청하는데, 아뿔싸! 11.11.11.11는 아무것도 없다.
만약 IP를 변경해야 한다면, 기존 웹서버는 당분간 그대로 살려놓은 후, TTL을 5분으로 설정하고 IP를 바꾼 후 다시 TTL을 늘려잡는게 좋다.
HTTP 개요
HTTP에 관한 내용은 바로 전 장인 네트워크/인터넷에서 약간 다룬 바 있다. 웹 브라우저에서 google.com 을 입력하면 구글의 첫 화면이 나오는 일련의 흐름 중 가장 상단에 위치한 프로토콜이 바로 HTTP(HyperText Transfer Protocol)이다.
HTTP의 특징1 - 간단하다
1989년 스위스 제네바에 있는 유럽 입자 물리학 연구소(CERN)에서 근무하고 있던 영국인 과학자 팀 버너스 리(Tim Berners-Lee) 박사와 동료들은 지식을 쉽게 검색하고 공유하기 위한 시스템을 고안했다. 이 시스템의 가장 큰 특징은 여러 문서 사이에 링크를 두고 참조를 할 수 있도록 하는 하이퍼텍스트(HyperText)이며, 이는 곧 월드 와이드 웹(WWW, World Wide Web)의 기반이 된다. 애당초 연구자료 공유를 위해 만들었기 때문에(논문을 생각하면 된다) HTTP는 태생 자체가 주로 텍스트를 전송하기 위한 프로토콜이었기 때문에 프로토콜 자체는 굉장히 간단하다.
HTTP의 특징2 - 클라이언트-서버 구성
HTTP는 웹 브라우저가 요청(Request)하고 누군가가 응답(Response)하는 형태이다. 프로토콜 유형으로는 클라이언트-서버 프로토콜이라고 구분하기도 한다. 요청하는 쪽을 클라이언트, 그 요청을 처리해서 응답하는 쪽을 서버(혹은 웹서버)라 한다. HTTP로 통신을 하기 위해서는 무조건 1:1 이어야 하며 누군가는 클라이언트, 다른 누군가는 서버의 역할을 담당해야 한다.
또한 통신은 반드시 클라이언트로부터 시작한다. 클라이언트가 요청을 보내야 서버가 응답을 하지, 클라이언트의 요청 없이 서버가 응답을 보내는 경우는 없다.
HTTP의 특징3 - 확장성
HTTP가 웹의 근간을 이룰 수 있는 이유는 HTTP 자체가 확장성이 좋기 때문이다. 확장의 중심에는 HTTP 헤더(Header)가 있다. 문자열 맵(Map)형태의 헤더는 서버와 클라이언트와 상호 합의만 된다면 얼마든지 새로운 기능을 추가할 수 있다.
상태 코드(Status Code)
프로그래머가 아닌 일반인이라도 인터넷을 돌아다니다보면 위와 같은 화면을 가끔 접한 경험이 있을 것이다. 이 404외에 500 Internal Server Error, 503 Service Unavailable 등등의 글자와 말이다. 이는 HTTP의 상태코드다. HTTP의 모든 요청에는 응답이 오는데 이 응답에는 상태를 나타내는 숫자가 있고 이를 상태 코드라고 한다.
상태 코드는 3자리 숫자에 불과하지만 굉장히 중요한 역할을 한다. 클라이언트는 이 상태 코드를 참고해서 에러 메시지를 띄우거나, 사용자의 요청을 처리한다. 그렇기 때문에 서버 입장에서는 요청에 대한 상태 코드를 잘 선택해야 한다.
HTTP에서의 상태 코드의 위치
서버 등에서 반환하는 응답 내용에서 상태 코드는 맨 첫 번째 줄에 위치한다. 첫 번째 줄에는 HTTP 버전, 상태 코드, 상태 메시지가 명시되어 있다.
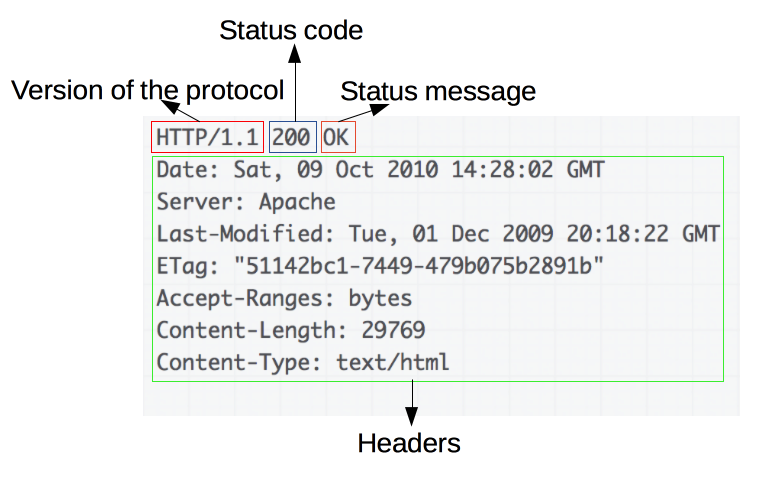
여기서 중요한건 상태 코드의 숫자다. 상태 메시지는 상태 코드에 대한 짧은 설명일 뿐이고 클라이언트의 동작에 아무 영향을 끼치지 않는다.
상태 코드의 대분류
상태 코드를 서버마다 제각각으로 쓴다면 곤란하다. 따라서 상태코드는 RFC 2616에 그 내용이 정의되어 있으며, IANA가 현재 공식 HTTP 상태 코드 레지스트리를 관리하고 있다. 상태코드는 첫 번째 자리의 숫자에 따라 크게 5가지 동작으로 구분할 수 있다.
조건부 응답(1xx)
서버는 클라이언트의 요청을 받았으며 작업을 계속 진행하고 있음을 의미한다. 클라이언트는 그냥 요청을 계속하던지, 서버의 요청에 따라 프로토콜을 업데이트 해야한다.
성공(2xx)
서버는 클라이언트의 요청을 확실히 이해했고, 성공적으로 이를 처리했음을 의미한다.
리다이렉트(3xx)
다른 리소스로 리다이렉트를 의미한다. 클라이언트는 3XX 상태코드가 담긴 응답을 받았을때 다른 리소스로 이동해야 한다.
클라이언트 에러(4xx)
에러가 났는데, 원인 제공자는 클라이언트라는 점을 의미한다. 보통 클라이언트가 규격에 맞지 않는 데이터를 보냈을 경우다. 서버 개발자 입장에서 볼때는 "니가 잘못했다", 클라이언트 개발자 입장에서 볼 때는 "내가 잘못했나?"로 요약할 수 있다.
서버 에러(5xx)
에러가 났는데, 원인 제공자는 서버라는 점을 의미한다. 클라이언트는 유효한 요청을 보냈지만 서버 측의 과실로 생긴 에러다. 서버 개발자 입장에서 볼때는 "내가 잘못했다", 클라이언트 개발자 입장에서 볼 때는 "서버 똑바로 안하냐?" 로 요약할 수 있다.
자주 사용하는 상태 코드
표준으로 정의된 상태 코드는 줄잡아 수 십개나 되지만, 현업에서는 모든 상태코드를 다 사용하지 않는다. 주로 아래와 같은 상태 코드만 사용한다.
200 OK
요청이 성공했음을 의미한다.
201 Created
리소스가 새로 생성됨을 의미한다. 보통 POST 요청에 대한 응답의 상태 코드로서 사용되며, 응답 바디에는 새로 생성된 리소스의 정보가 들어가는 경우가 많다.
301 Moved Permanently
클라이언트가 요청한 리소스가 영구적으로 새로운 URI로 이동했다는 사실을 의미한다.
302 Found (혹은 Moved temporarily)
클라이언트가 요청한 리소스가 임시로 다른 URI로 이동했다는 사실을 의미한다. SEO에서는 301과 302를 잘 써야한다. 웹사이트 도메인을 변경했다면 301을 써야하며, 사이트 정비나 기타 문제로 임시로 이동했을 경우 302를 사용해야 한다.
400 Bad Request
웹개발을 한다면 200과 함께 가장 많이 볼 상태 코드다. 클라이언트의 요청이 잘못되었다는 사실을 의미한다.
401 Unauthorized
해당 리소스를 접근할때 적절한 인증 정보가 없다는 사실을 의미한다.
403 Forbidden
클라이언트는 올바른 정보를 요청하고 유효한 인증 정보는 있지만 리소스를 접근하기에 충분한 권한을 가지지 못하고 있다는 의미이다. 401과 비슷한다만 다른 점을 쉽게 설명하자면 출입카드가 없는 경우가 401이며, 지금 내가 가진 출입카드로 건물은 들어갔지만 1급 비밀 보관소에 못들어가면 403이다.
404 Not Found
클라이언트가 요청한 리소스가 없음을 의미한다.
405 Method Not Allowed
클라이언트가 요청한 리소스가 있지만 HTTP 메소드가 다를 경우다. 예를 들어 서버에서는 GET www.example.com 만을 지원하지만 클라이언트가 POST로 보내는 경우가 이에 해당된다.
409 Conflict
리소스의 현재 상태와 클라이언트의 요청(주로 생성 및 업데이트)이 충돌이 날 경우를 의미한다.
500 Internal Server Error
서버에 이상이 생겨서 요청에 대해 응답을 할 수 없음을 의미한다.

503 Service Unavailable
서버가 클라이언트의 요청을 처리할 수 없음을 의미한다. 서버 내부 설정을 잘못 했거나, 처리량이 너무 많아서 응답을 못해주는 등 이유야 여러 가지가 있다.
전체 HTTP 상태 코드는 위키피디아를 참고하시기 바랍니다.